Un optimiseur de localisation décentralisé qui résout 11× plus de scénarios que le MILP de référence
Gestion de capacité par file de priorité + Progressive Scenario Expansion ; sur le vrai dataset de localisation de Gymnasien de Dresde il résout 14 écoles × 558 élèves × 110 scénarios en 24 heures, là où le MILP de référence cale au-delà de 10 scénarios
Où mettre la prochaine école, la prochaine borne de recharge, le prochain showroom ? Les modèles traditionnels de localisation supposent qu'un planificateur central affecte les clients aux facility. Les vrais clients ne prennent pas d'ordres, ils choisissent. Nous avons mis cette observation au cœur de l'optimisation.
Notre cadre intègre une demande de choix discret riche et des contraintes de capacité (gérées via files de priorité décentralisées) dans un seul MILP, plus un solveur Progressive Scenario Expansion qui gère des instances à 14 emplacements, 558 clients, 110 scénarios d'un vrai dataset suisse de localisation d'écoles, des tailles d'instance que le MILP de référence ne peut pas dépasser au-dessus de R = 10 scénarios.
Le défi
Le Capacitated Facility Location Problem (CFLP) est un classique de la RO, mais les formulations classiques centralisent l'affectation client, l'opérateur décide non seulement où ouvrir des facility mais aussi qui va où. C'est bien pour les entrepôts et centres de distribution ; c'est faux pour tout cadre où les individus choisissent librement (écoles, retail, recharge EV, santé). Branchez un modèle centralisé sur le problème d'allocation scolaire et l'optimiseur route les enfants vers n'importe quelle école qui maximise l'objectif du planificateur, même si l'enfant n'y irait jamais.
Corriger cela demande trois choses en même temps : une demande de choix discret riche côté client (qui tue les probabilités de choix en forme close et force la simulation), des contraintes de capacité exprimées à l'échelle individuelle (qui couplent chaque client à chaque autre via la file de priorité), et une réflexion en parts de marché consciente des concurrents. Mettre les trois dans un seul MILP tractable, et le résoudre sur des instances réelles, était le défi ouvert.
Notre démarche
Nous avons adapté le cadre MILP basé sur la simulation de Pacheco-Paneque et al. de la tarification au contexte CFLP, transformant chaque scénario Monte Carlo en une trajectoire de choix déterministe et agrégeant la capture de marché (la part d'individus qui choisissent effectivement l'une des facility de l'opérateur) comme objectif, plutôt que la somme d'utilité centralisée qui distord l'affectation.
La capacité est imposée via des listes de priorité exogènes : chaque individu est traité dans l'ordre de la file, et la variable de disponibilité y_inr d'une facility bascule à 0 dès que ses sélections cumulées atteignent sa capacité c_i. Cela décentralise la décision d'affectation tout en gardant la formulation linéaire via des astuces d'utilité escomptée.
Nous avons ajouté deux inégalités valides (effet de chaîne de priorité et liaison de budget de capacité agrégé), une passe de prétraitement d'utilité qui élimine les triplets facility/individu/scénario dominés en amont, et une méthode Progressive Scenario Expansion (PSE) qui résout une séquence de sous-problèmes imbriqués avec des ensembles de scénarios à croissance géométrique, chaque résolution warm-startant depuis la précédente. Le taux de croissance base 1,7, combiné à inégalité de priorité + warm-start complet + ordre des scénarios par entropie étendue, est la configuration gagnante.
Le résultat
Livrable : un cadre de localisation de facility capacitée décentralisé qui intègre tout modèle de choix discret avancé dans le MILP, plus une méthode de résolution Progressive Scenario Expansion (PSE) qui le passe à l'échelle bien au-delà du MILP de référence. Sur le vrai dataset de localisation de Gymnasien de Dresde (Haase et Müller 2013, 14 écoles candidates = 12 publiques + 2 privées toujours ouvertes, budget 6 M€), la PSE la mieux configurée résout des instances jusqu'à 14 écoles × 558 élèves × 110 scénarios dans une limite de 24 heures. Le RAW MILP de référence cale au-delà de 10 scénarios sur les mêmes instances — une augmentation de 11× du nombre de scénarios résolvables.
Sur données synthétiques, la meilleure configuration PSE (base 1,7 + inégalités valides de priorité + warm-start complet + ordre par entropie étendue) atteint jusqu'à 95 % de réduction de temps par rapport à la configuration de base, et 28 % de réduction par rapport au RAW MILP sur les instances que les deux résolvent. L'inégalité valide de chaîne de priorité seule délivre 40–60 % d'accélération ; le reste vient de l'expansion de scénarios + warm-start + ordre par entropie.
Plongée technique
Le modèle derrière le résultat.
Le modèle
Tout l'astuce de ce travail est d'encoder trois choses couplées dans un MILP : qui choisit quoi (maximisation d'utilité par choix discret à l'échelle individuelle), qui obtient une place (dépendance de capacité par file de priorité entre chaque paire de clients), et où placer les facility (la décision stratégique). Le modèle vit dans un cadre Sample Average Approximation, nous tirons R scénarios Monte Carlo des termes d'utilité aléatoires, figeons tout dans chaque scénario, et laissons les variables binaires de choix w_inr propager via les contraintes de disponibilité et de capacité. Le résultat est une formulation entièrement linéaire qui capture le comportement client décentralisé sans jamais calculer de probabilité de choix en forme close.
Objectif de capture maximale. Somme sur scénarios, facility et individus de la variable binaire de choix w_inr (1 ssi l'individu n choisit la facility opérateur i en scénario r), normalisée par 1/R. Chaque client choisit exactement une option (facility opérateur ou opt-out concurrent 0). Coût total d'ouverture sous budget B. C'est l'analogue décentralisé du CFLP classique, l'opérateur choisit les ouvertures y_i ; les clients choisissent les facility w_inr.
Utilité escomptée z_inr. Pour imposer que les clients maximisent l'utilité *uniquement sur les facility disponibles*, nous masquons l'utilité des options indisponibles en la remplaçant par une constante L en dessous de toute valeur d'utilité faisable. Le client choisit alors l'alternative avec la plus haute utilité escomptée, qui par construction est forcément une facility disponible. La linéarisation big-M gère la définition conditionnelle.
Contraintes de capacité par file de priorité. (A-O) La disponibilité exige que la facility soit ouverte. (CAP1) Les sélections cumulées de la facility i par tous les clients de priorité supérieure (m = 1, …, n − 1) ne peuvent excéder c_i − 1 si la facility i est encore disponible pour n. (CAP2) Si la facility i est ouverte et non pleine quand n arrive, elle *doit* être marquée disponible, ce qui empêche le solveur de fermer artificiellement une facility à un client juste pour améliorer l'objectif centralisé. (CAP2) est ce qui rend le cadre vraiment décentralisé plutôt qu'une relaxation.
Inégalité valide de chaîne de priorité. Si la facility i était disponible pour le client n et que le client n ne l'a pas prise, alors elle doit être encore disponible pour le client n+1. C'est l'inégalité qui achète 40–60 % d'amélioration de temps à elle seule, elle informe Gurobi d'une relation structurelle entre variables de disponibilité consécutives que la formulation originale laisse implicite. Sans elle, le solveur la redécouvre depuis zéro à chaque nœud.
Prétraitement d'utilité. Pour chaque triplet (i, n, r), calculer les bornes inférieure et supérieure sur l'utilité de l'opérateur versus le meilleur concurrent. Si l'opérateur domine le concurrent sur tout l'intervalle faisable, le client est capturé déterministe, éliminer les variables de choix du triplet et ajouter la contribution comme constante à l'objectif. Symétriquement, si le concurrent domine l'opérateur sur tout l'intervalle, le triplet n'est jamais capturé, le supprimer. Les deux directions réduisent la taille du modèle avant même que le solveur ne démarre.
Progressive Scenario Expansion. Au lieu de résoudre le MILP complet avec R scénarios dès le départ, résoudre une séquence de sous-problèmes imbriqués où l'ensemble de scénarios croît d'un facteur multiplicatif fixe λ. Chaque sous-problème warm-start depuis le précédent. Le taux de croissance λ = 1,7 a été identifié empiriquement comme le point d'équilibre : assez grand pour terminer en un nombre raisonnable d'étapes, assez petit pour que les sous-problèmes consécutifs partagent assez de structure pour que le warm-start porte une vraie information. λ = 1,1 meurt en étapes ; λ ≥ 2 perd l'avantage du warm-start.
Ordre de scénarios par entropie étendue. Pour choisir quels scénarios entrent en premier dans l'ensemble actif, nous clusterisons les scénarios par leur schéma de choix réalisé et les rangeons par entropie d'appartenance de cluster, les scénarios à haute entropie passent en premier car ils portent le plus d'information sur le paysage de choix. L'ordre aléatoire, à l'inverse, dépense souvent les premières étapes sur des quasi-doublons les uns des autres, gaspillant les warm-starts précoces.
Le stack PSE + inégalités valides + prétraitement d'utilité est ce qui transforme un MILP de manuel en un outil capable de résoudre des instances de localisation réalistes sous choix client décentralisé. Aucun des quatre ingrédients seul ne suffit, la méthode RAW avec seulement les inégalités de priorité peut résoudre 10 scénarios ; PSE sans inégalités de priorité est plus lent que RAW ; PSE avec toutes les fonctionnalités est la seule méthode qui passe 50 scénarios sur le dataset scolaire. La limite affichée (14 écoles × 558 élèves × 110 scénarios en 24 h 57 min) est encore bien en deçà du dataset original 26 écoles × 1 343 élèves, que la thèse signale comme la prochaine direction de recherche naturelle, probablement via les méthodes heuristiques développées dans la lignée BHA / BHAMSLE.
Benchmark
Test sur le dataset suisse de localisation scolaire de Haase et Müller (2013) : 14 écoles candidates (12 publiques + 2 privées toujours ouvertes), coût et capacité réels par école, distributions et profils de choix réels d'élèves. Temps en secondes ; limite 24 heures (86 400 s). Chaque méthode testée avec sa ‘meilleure' configuration : RAW + inégalité de priorité ; PSE base 1,7 + inégalité de priorité + warm-start complet + ordre par entropie étendue. ‘DNF' = non terminé en 24 h.
| Scénarios R | RAW + Priority VI | PSE base 1.7 (Best) | Ratio PSE 1.7 / RAW |
|---|---|---|---|
| 1 | 35 s | 49 s | 1,40× |
| 5 | 444 s | 1 312 s | 2,95× |
| 10 | 3 861 s | 4 511 s | 1,17× |
| 50 | DNF (> 86 400 s) | 7 936 s | 0,09× (PSE 10× plus rapide) |
| 100 | DNF (> 86 400 s) | 21 530 s | 0,25× (PSE 4× plus rapide) |
Deux régimes. Sous R ≈ 10 scénarios, le RAW MILP gagne, pas la peine de faire de l'expansion de scénarios quand l'instance complète est déjà petite. Au-dessus de R ≈ 10 le RAW MILP s'effondre (le nombre de variables croît en J × N × R et le branch-and-cut de Gurobi ne peut suivre la combinatoire par scénario), et la méthode PSE est la seule qui termine. Le régime à 50 scénarios est le passage où PSE passe de ‘plus lent' à ‘la seule option qui marche', et c'est précisément le régime dont les problèmes pratiques de localisation basés sur simulation ont besoin (la littérature exige typiquement 100–1 000 scénarios pour des estimations stables de probabilités de choix). Sur données synthétiques avec taille d'instance contrôlée, la PSE 1,7 meilleure configuration tourne 85–95 % plus vite que sa propre configuration de base (pas d'inégalités, ordre aléatoire, warm-start partiel), montrant que chaque feature du stack contribue.
Tiré du dossier

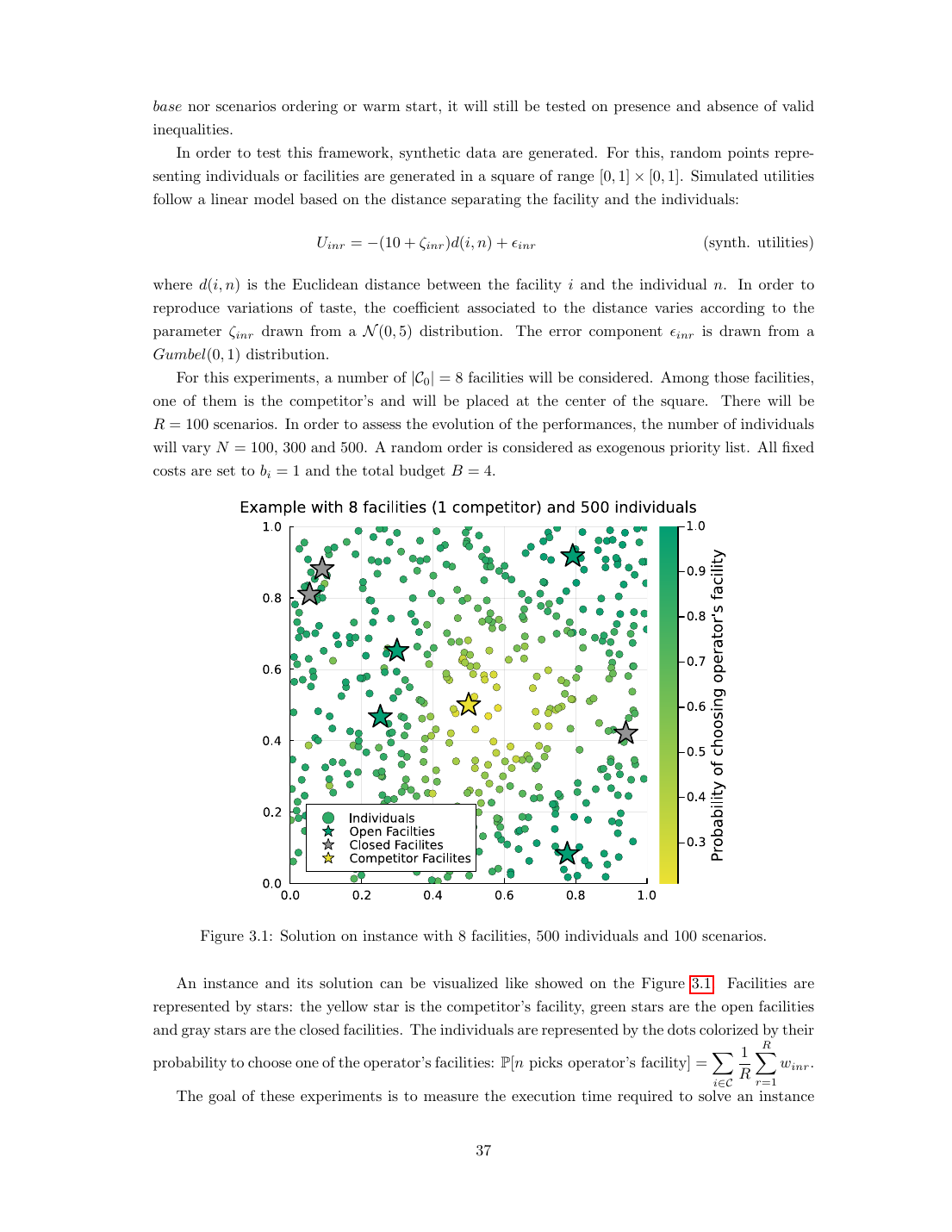

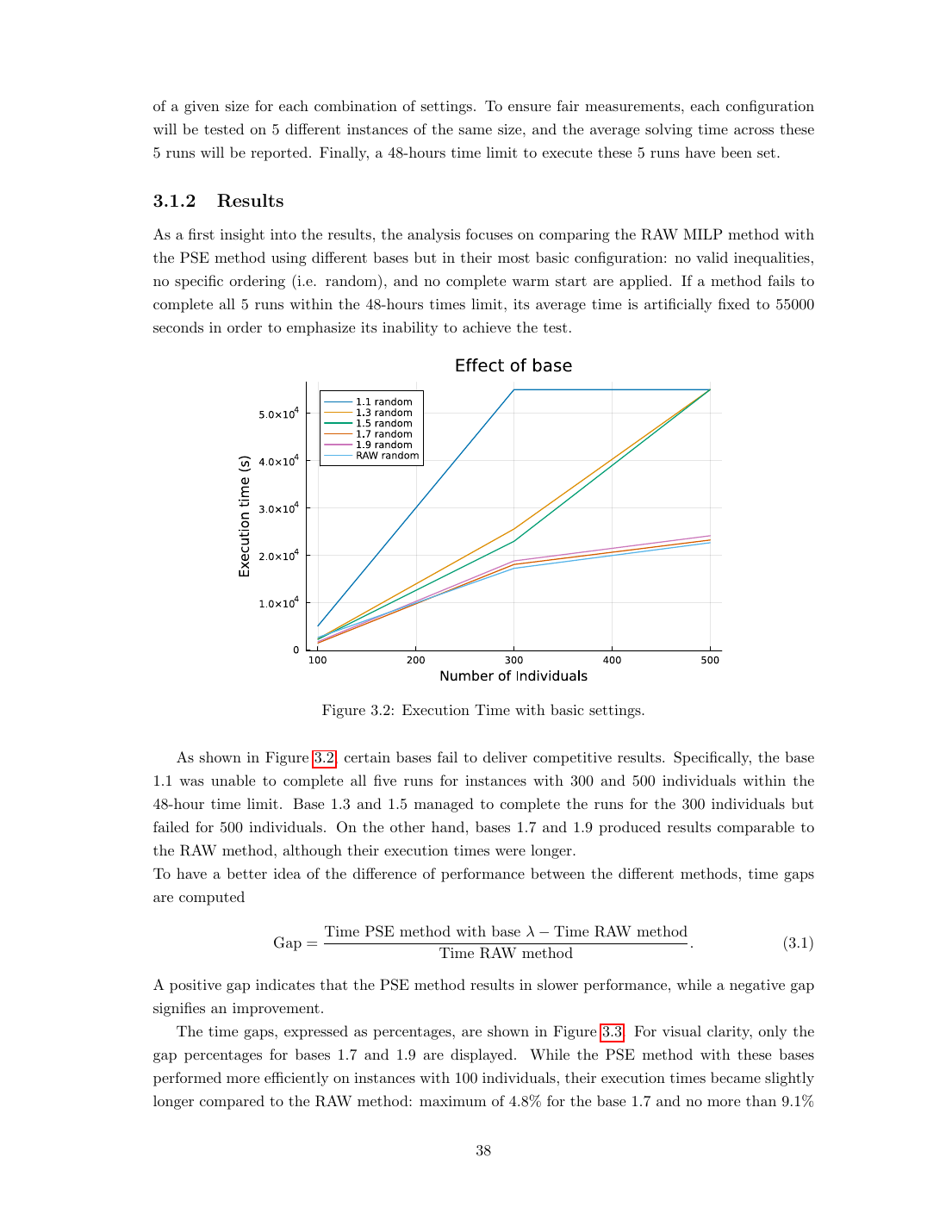
Techniques
- Localisation de facility capacitée décentralisée
- MILP basé sur la simulation (SAA)
- Choix discret avec concurrents
- Progressive Scenario Expansion
- Inégalités valides de chaîne de priorité
- Ordre des scénarios par entropie
Stack
- Julia
- Gurobi 10.0.1
- Dataset suisse de localisation scolaire (Haase & Müller 2013)
Un problème de ce type ?