Ein dezentralisierter Standortwahl-Optimierer, der 11× mehr Szenarien als das Lehrbuch-MILP löst
Prioritätswarteschlangen-Kapazitätsbehandlung + Progressive Scenario Expansion; auf dem echten Dresdener Gymnasial-Standort-Datensatz löst er 14 Schulen × 558 Schüler × 110 Szenarien in 24 Stunden, wo das Lehrbuch-MILP über 10 Szenarien hinaus ins Stocken gerät
Wo platziert man die nächste Schule, die nächste Ladestation, den nächsten Showroom? Traditionelle Standortwahl-Modelle nehmen an, dass ein zentraler Planer Kunden Einrichtungen zuweist. Echte Kunden nehmen keine Anweisungen entgegen, sie wählen. Wir haben diese Beobachtung ins Herz der Optimierung gebracht.
Unser Framework integriert reiche Discrete-Choice-Nachfrage und Kapazitäts-Constraints (über dezentralisierte Prioritätswarteschlangen) in ein einziges MILP, plus ein Progressive-Scenario-Expansion-Solver, der 14-Standort-, 558-Kunden-, 110-Szenarien-Instanzen eines echten Schweizer Schulstandort-Datensatzes löst, Instanzgrössen, an die das Lehrbuch-MILP über R = 10 Szenarien hinaus nicht herankommt.
Die Herausforderung
Das Capacitated Facility Location Problem (CFLP) ist ein OR-Klassiker, aber klassische Formulierungen zentralisieren die Kundenzuweisung, der Betreiber entscheidet nicht nur, wo Einrichtungen geöffnet werden, sondern auch, wer wohin geht. Das ist okay für Lager und Distributionszentren; falsch für jedes Setting, in dem Individuen frei wählen (Schulen, Detailhandel, EV-Ladung, Gesundheitsversorgung). Schaltet man ein zentralisiertes Modell auf das Schulzuweisungs-Problem, routet der Optimierer Kinder zur Schule, die die Zielfunktion des Planers maximiert, auch wenn das Kind dort nie hingehen würde.
Das zu beheben braucht drei Dinge gleichzeitig: reiche Discrete-Choice-Nachfrage auf der Kundenseite (was geschlossen-formige Choice-Wahrscheinlichkeiten tötet und Simulation erzwingt), Kapazitäts-Constraints auf Individuen-Ebene (was jeden Kunden mit jedem anderen über die Prioritätswarteschlange koppelt) und wettbewerbsbewusstes Marktanteils-Denken. Alle drei in ein einziges traktables MILP zu pressen, und auf realen Instanzen zu lösen, war die offene Herausforderung.
Unser Vorgehen
Wir haben das simulationsbasierte MILP-Framework von Pacheco-Paneque et al. von Pricing auf den CFLP-Kontext adaptiert, jedes Monte-Carlo-Szenario in eine deterministische Choice-Trajektorie verwandelt und Marktanteils-Capture (der Anteil der Individuen, die tatsächlich eine der Einrichtungen des Betreibers wählen) als Zielfunktion aggregiert, statt der zentralisierten Nutzen-Summe, die die Zuweisung verzerrt.
Kapazität wird über exogene Prioritätslisten erzwungen: Jedes Individuum wird in Warteschlangenreihenfolge verarbeitet, und die Verfügbarkeits-Variable y_inr einer Einrichtung kippt in dem Moment auf 0, in dem ihre kumulierten Auswahlen die Kapazität c_i erreichen. Das dezentralisiert die Zuweisungsentscheidung und hält die Formulierung gleichzeitig linear über Diskontierte-Nutzen-Tricks.
Wir haben zwei gültige Ungleichungen hinzugefügt (Prioritätsketten-Effekt und aggregierte Kapazitätsbudget-Verknüpfung), einen Nutzen-Preprocessing-Pass, der dominierte Einrichtungs-Individuum-Szenario-Tupel im Voraus eliminiert, und eine Progressive-Scenario-Expansion-Methode (PSE), die eine Folge ineinander geschachtelter Subprobleme mit geometrisch wachsenden Szenario-Sets löst und jedes Subproblem aus dem vorherigen warmstartet. Die Basis-1,7-Wachstumsrate, kombiniert mit Prioritäts-Ungleichung + komplettem Warmstart + Extended-Entropy-Szenarienordnung, ist die Gewinnkonfiguration.
Das Ergebnis
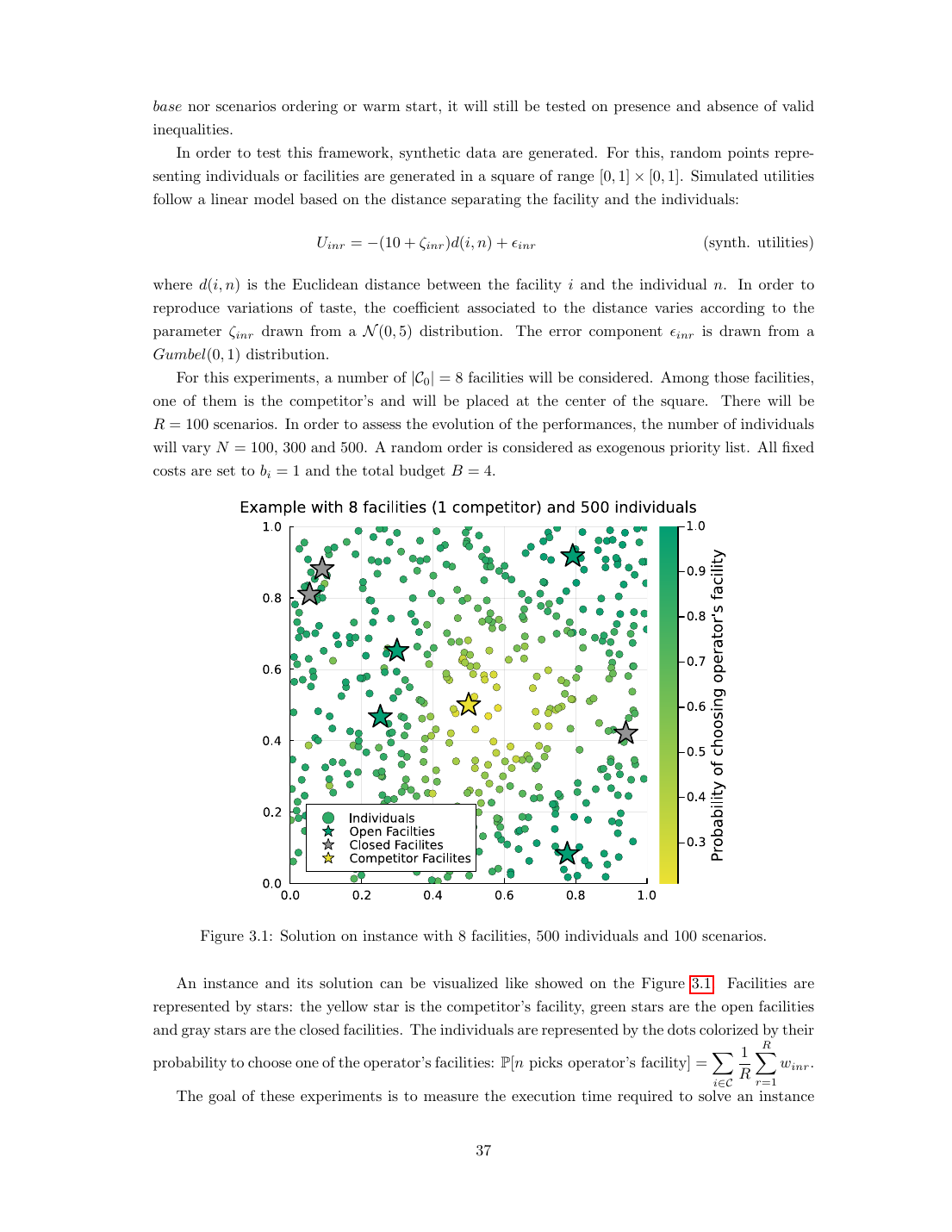
Deliverable: ein dezentralisiertes kapazitiertes Standortwahl-Framework, das jedes fortgeschrittene Discrete-Choice-Modell ins MILP integriert, plus eine Progressive-Scenario-Expansion-Lösemethode (PSE), die es weit über das Lehrbuch-MILP hinaus skaliert. Auf dem echten Dresdener Gymnasial-Standort-Datensatz (Haase und Müller 2013, 14 Kandidatenschulen = 12 öffentliche + 2 immer offene private, €6 Mio. Budget) löst die best-konfigurierte PSE Instanzen von bis zu 14 Schulen × 558 Schülern × 110 Szenarien innerhalb eines 24-Stunden-Limits. Das Lehrbuch-RAW-MILP gerät auf denselben Instanzen über 10 Szenarien hinaus ins Stocken — ein 11×-Anstieg der lösbaren Szenarienanzahl.
Auf synthetischen Daten erreicht die beste PSE-Konfiguration (Basis 1,7 + Prioritäts-gültige-Ungleichungen + vollständiger Warmstart + Extended-Entropy-Ordering) bis zu 95 % Laufzeitreduktion gegenüber der Basis-Konfiguration und 28 % Reduktion gegenüber dem RAW-MILP auf Instanzen, die beide lösen können. Die Prioritäts-gültige-Ungleichung allein liefert 40–60 % Speed-up; der Rest kommt aus Szenarienexpansion + Warmstart + Entropie-basierter Ordnung.
Technischer Deep Dive
Das Modell hinter dem Ergebnis.
Das Modell
Der ganze Trick dieser Arbeit ist, drei gekoppelte Dinge in einem MILP zu kodieren: wer was wählt (Discrete-Choice-Nutzenmaximierung auf Individuen-Ebene), wer einen Platz bekommt (Prioritätswarteschlangen-Kapazitätsabhängigkeit zwischen jedem Kundenpaar) und wo Einrichtungen platziert werden (die strategische Entscheidung). Das Modell lebt in einem Sample-Average-Approximation-Rahmen, wir ziehen R Monte-Carlo-Szenarien der zufälligen Nutzenterme, fixieren in jedem Szenario alles und lassen die binären Choice-Variablen w_inr durch Verfügbarkeits- und Kapazitäts-Constraints propagieren. Das Ergebnis ist eine vollständig lineare Formulierung, die dezentralisiertes Kundenverhalten erfasst, ohne je eine geschlossen-formige Choice-Wahrscheinlichkeit zu berechnen.
Maximum-Capture-Zielfunktion. Summe über Szenarien, Einrichtungen und Individuen der binären Choice-Variable w_inr (1 genau dann, wenn Individuum n in Szenario r die Einrichtung i des Betreibers wählt), normalisiert mit 1/R. Jeder Kunde wählt genau eine Option (Einrichtung des Betreibers oder Wettbewerber-Opt-out 0). Gesamteröffnungskosten unter Budget B. Das ist das dezentralisierte Pendant des klassischen CFLP, der Betreiber wählt Eröffnungen y_i; die Kunden wählen Einrichtungen w_inr.
Diskontierter Nutzen z_inr. Damit Kunden Nutzen *nur über verfügbare Einrichtungen* maximieren, maskieren wir den Nutzen nicht-verfügbarer Optionen, indem wir ihn durch eine Konstante L unterhalb jedes zulässigen Nutzens ersetzen. Der Kunde wählt dann die Alternative mit dem höchsten diskontierten Nutzen, die konstruktiv nur eine verfügbare Einrichtung sein kann. Big-M-Linearisierung behandelt die bedingte Definition.
Prioritätswarteschlangen-Kapazitäts-Constraints. (A-O) Verfügbarkeit setzt voraus, dass die Einrichtung geöffnet ist. (CAP1) Die kumulierten Auswahlen der Einrichtung i durch alle höher priorisierten Kunden (m = 1, …, n − 1) dürfen c_i − 1 nicht übersteigen, falls i für n noch verfügbar ist. (CAP2) Falls i geöffnet und nicht voll ist, wenn n ankommt, *muss* sie als verfügbar markiert werden, das verhindert, dass der Solver eine Einrichtung künstlich für einen Kunden schliesst, um die zentralisierte Zielfunktion zu verbessern. (CAP2) ist, was das Framework wirklich dezentralisiert macht statt eine Relaxierung.
Prioritätsketten-gültige-Ungleichung. Wenn Einrichtung i für Kunde n verfügbar war und Kunde n sie nicht genommen hat, muss sie auch für Kunde n+1 noch verfügbar sein. Diese Ungleichung allein bringt 40–60 % Laufzeitverbesserung, sie teilt Gurobi eine strukturelle Beziehung zwischen aufeinanderfolgenden Verfügbarkeitsvariablen mit, die die Originalformulierung implizit lässt. Ohne sie entdeckt der Solver das an jedem Knoten von Null neu.
Nutzen-Preprocessing. Für jedes Tupel (i, n, r) berechnen wir untere und obere Schranken auf den Nutzen des Betreibers versus den besten Wettbewerber. Wenn der Betreiber den Wettbewerber über den gesamten zulässigen Bereich dominiert, ist der Kunde deterministisch erfasst, eliminiere die Choice-Variablen des Tupels und ergänze den Beitrag als Konstante in der Zielfunktion. Symmetrisch: Wenn der Wettbewerber den Betreiber im gesamten Bereich dominiert, wird das Tupel nie erfasst, verwerfen. Beide Richtungen reduzieren die Modellgrösse, bevor der Solver überhaupt startet.
Progressive Scenario Expansion. Statt das volle MILP mit R Szenarien von Anfang an zu lösen, lösen wir eine Folge geschachtelter Subprobleme, in denen das Szenario-Set um einen festen multiplikativen Faktor λ wächst. Jedes Subproblem warmstartet aus dem vorherigen. Die Wachstumsrate λ = 1,7 wurde empirisch als Sweet Spot identifiziert: gross genug, um in einer angemessenen Anzahl Stufen zu terminieren, klein genug, dass aufeinanderfolgende Subprobleme genug Struktur teilen, damit der Warmstart echte Information trägt. λ = 1,1 stirbt in Stufen; λ ≥ 2 verliert den Warmstart-Vorteil.
Extended-Entropy-Szenarienordnung. Um zu wählen, welche Szenarien zuerst in das aktive Set kommen, gruppieren wir Szenarien nach ihrem realisierten Wahlmuster und ordnen sie nach der Entropie der Cluster-Mitgliedschaft, Hoch-Entropie-Szenarien kommen zuerst, weil sie die meiste Information über die Choice-Landschaft tragen. Zufallsordnung hingegen verbringt die ersten Stufen oft auf Beinahe-Duplikaten voneinander und verschwendet die frühen Warmstarts.
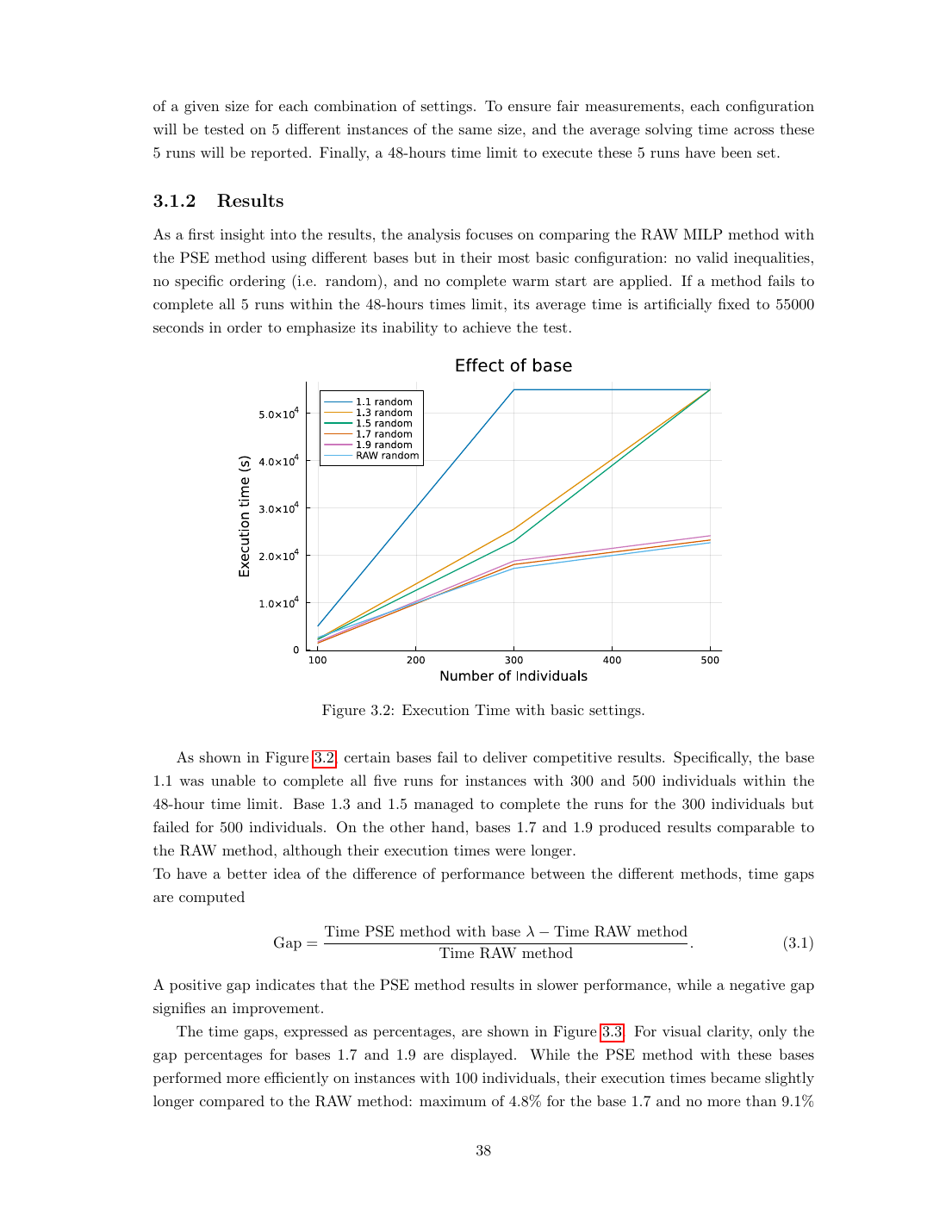
Die Stack-Kombination PSE + gültige Ungleichungen + Nutzen-Preprocessing macht aus einem Lehrbuch-MILP ein Werkzeug, das realistische Standortwahl-Instanzen unter dezentralisierter Kundenauswahl tatsächlich lösen kann. Keine der vier Zutaten allein reicht, die RAW-Methode mit nur Prioritäts-Ungleichungen löst 10 Szenarien; PSE ohne Prioritäts-Ungleichungen ist langsamer als RAW; PSE mit allen Features ist die einzige Methode, die 50 Szenarien auf dem Schulstandort-Datensatz knackt. Die Headline-Grenze (14 Schulen × 558 Schüler × 110 Szenarien in 24 h 57 min) ist immer noch weit vom Original-26-Schulen × 1 343-Schüler-Datensatz entfernt, den die Thesis als natürliche nächste Forschungsrichtung markiert, wahrscheinlich über die heuristischen Methoden, die in der verwandten BHA/BHAMSLE-Linie entwickelt werden.
Benchmark
Test auf dem Schweizer Schulstandort-Datensatz von Haase und Müller (2013): 14 Kandidaten-Schulen (12 öffentlich + 2 immer-offen privat), reale Kosten und Kapazitäten pro Schule, reale Schülerverteilungen und Wahl-Profile. Zeiten in Sekunden; 24-Stunden-Zeitlimit (86 400 s). Jede Methode mit ihrer ‘besten’ Konfiguration getestet: RAW + Prioritäts-Ungleichung; PSE mit Basis 1,7 + Prioritäts-Ungleichung + komplettem Warmstart + Extended-Entropy-Ordnung. ‘DNF’ = nicht in 24 h beendet.
| Szenarien R | RAW + Priority VI | PSE base 1.7 (Best) | PSE 1.7 / RAW Ratio |
|---|---|---|---|
| 1 | 35 s | 49 s | 1,40× |
| 5 | 444 s | 1 312 s | 2,95× |
| 10 | 3 861 s | 4 511 s | 1,17× |
| 50 | DNF (> 86 400 s) | 7 936 s | 0,09× (PSE 10× schneller) |
| 100 | DNF (> 86 400 s) | 21 530 s | 0,25× (PSE 4× schneller) |
Zwei Regime. Unter R ≈ 10 Szenarien gewinnt das RAW-MILP, es macht keinen Sinn, Szenarien zu expandieren, wenn die volle Instanz schon klein ist. Über R ≈ 10 kollabiert das RAW-MILP (die Variablenzahl wächst als J × N × R, und Gurobis Branch-and-Cut kann mit der Per-Szenario-Kombinatorik nicht mithalten), und die PSE-Methode ist die einzige, die fertig wird. Das 50-Szenario-Regime ist der Crossover, an dem PSE von ‘langsamer’ zu ‘einziger funktionierender Option’ wechselt, genau das Regime, das praktische simulationsbasierte Standortwahl-Probleme brauchen (die Literatur verlangt typischerweise 100–1 000 Szenarien für stabile Choice-Wahrscheinlichkeits-Schätzer). Auf synthetischen Daten mit kontrollierter Instanzgrösse läuft die PSE 1,7-Best-Konfiguration 85–95 % schneller als ihre eigene Basis-Konfiguration (keine Ungleichungen, zufällige Ordnung, partieller Warmstart), was zeigt, dass jedes Feature im Stack beiträgt.
Aus den Unterlagen


Techniken
- Dezentralisierte kapazitierte Standortwahl
- Simulationsbasiertes MILP (SAA)
- Discrete Choice mit Wettbewerbern
- Progressive Scenario Expansion
- Prioritätsketten-gültige-Ungleichungen
- Entropiebasierte Szenarienordnung
Stack
- Julia
- Gurobi 10.0.1
- Schweizer Schulstandort-Datensatz (Haase & Müller 2013)
Ein Problem wie dieses?