Ensembles de choix mode-et-destination conjoints, désormais en production dans le pipeline OASIS de l'EPFL
Première méthode à capturer le couplage mode/destination conjointement, avec un terme de correction de biais en forme close qui se branche dans tout estimateur de modèle activity-based
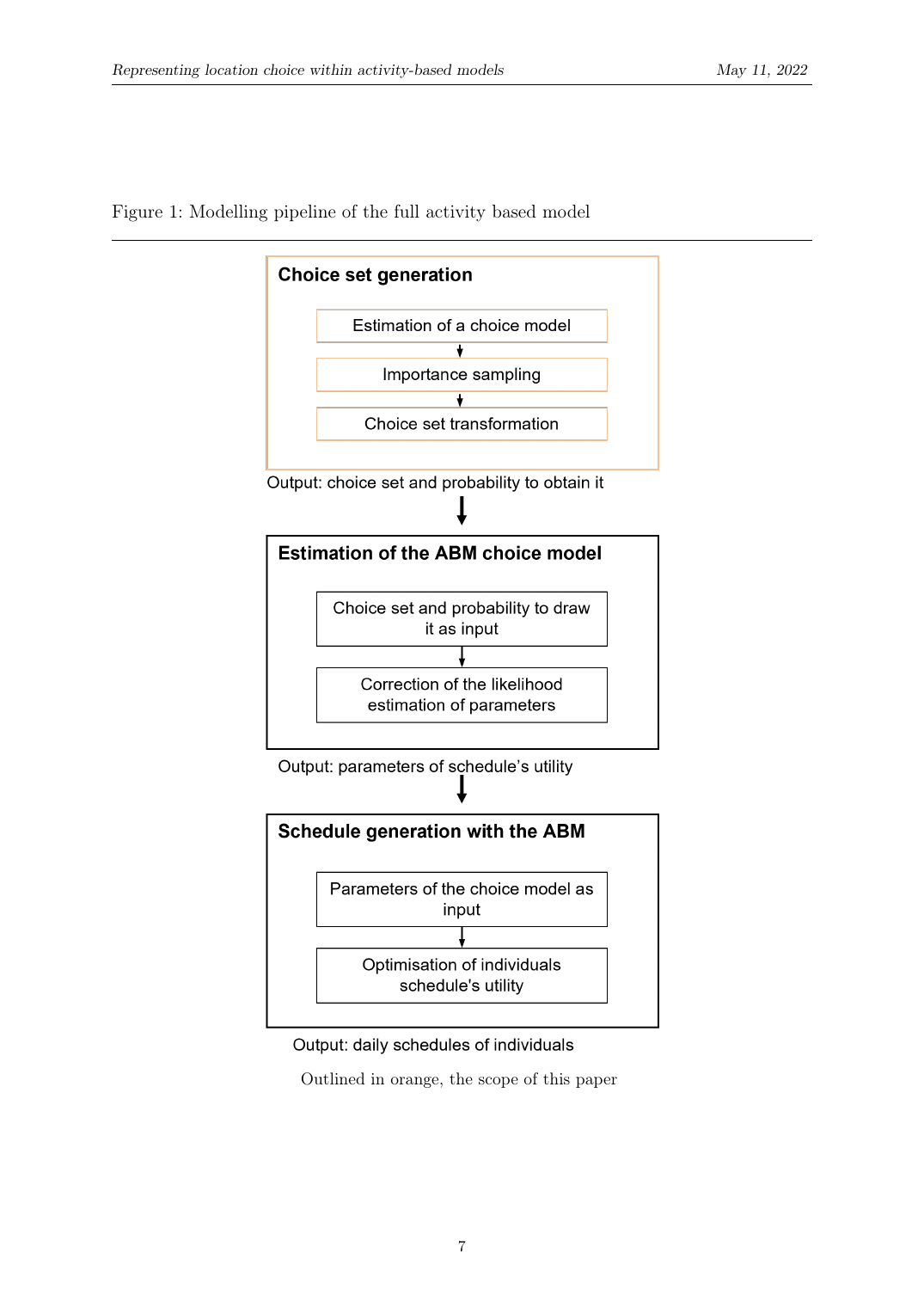
Les modèles de transport activity-based vivent et meurent par leurs ensembles de choix. Utilisez l'univers de chaque destination possible et l'estimation de paramètres rampe. Utilisez un filtre naïf et vous biaisez le modèle. Utilisez des heuristiques rigides basées sur la distance et vous ne capturez pas l'interaction mode-destination.
Nous avons co-rédigé une approche stochastique de génération d'ensembles de choix conjointe : estimer un cross-nested logit sur les combinaisons mode-et-destination observées, faire de l'importance sampling à partir de la distribution de probabilité résultante, puis perturber l'ensemble échantillonné avec trois opérateurs aléatoires pour injecter des alternatives improbables, donnant des ensembles compétitifs pour la simulation et un mélange contrôlé d'options probables/improbables pour une estimation de paramètres non biaisée.
Le défi
Sur des décennies de recherche, la génération d'ensembles de choix en modélisation activity-based a été traitée comme une étape de prétraitement fixe, souvent arbitraire, typiquement basée sur des filtres de distance ou de temps fondés sur des règles (prisme spatio-temporel de Hägerstrand, ellipses d'activité de Schönfelder-Axhausen, rubber-banding de Scherr et al.). Le résultat : des estimations de paramètres biaisées, un réalisme de simulation dégradé, et aucun moyen de capturer le vrai couplage entre décisions de mode et de destination (une voiture vous donne des destinations inaccessibles en transports publics ; voyager à l'heure de pointe rend les destinations plus proches plus attractives).
Le défi : construire une méthode qui génère des ensembles de choix simultanément utiles pour la simulation (alternatives compétitives) et l'estimation (mélange contrôlé d'options probables et improbables), et qui capture l'interaction entre mode et destination, pas un à la fois. Avec 88 zones × 3 modes même dans une petite étude de cas, cela fait 264 alternatives universelles par individu ; pour les 8 000 zones suisses, l'ensemble universel est 24 000.
Notre démarche
Nous estimons un cross-nested logit (CNL) sur les combinaisons mode-et-destination observées dans un journal de déplacements. La structure CNL place chaque alternative dans deux nids simultanément : un correspondant à son mode de transport (corrélation de mode entre alternatives accédées de la même façon), un correspondant à son groupe géographique (corrélation spatiale entre zones proches du même équipement).
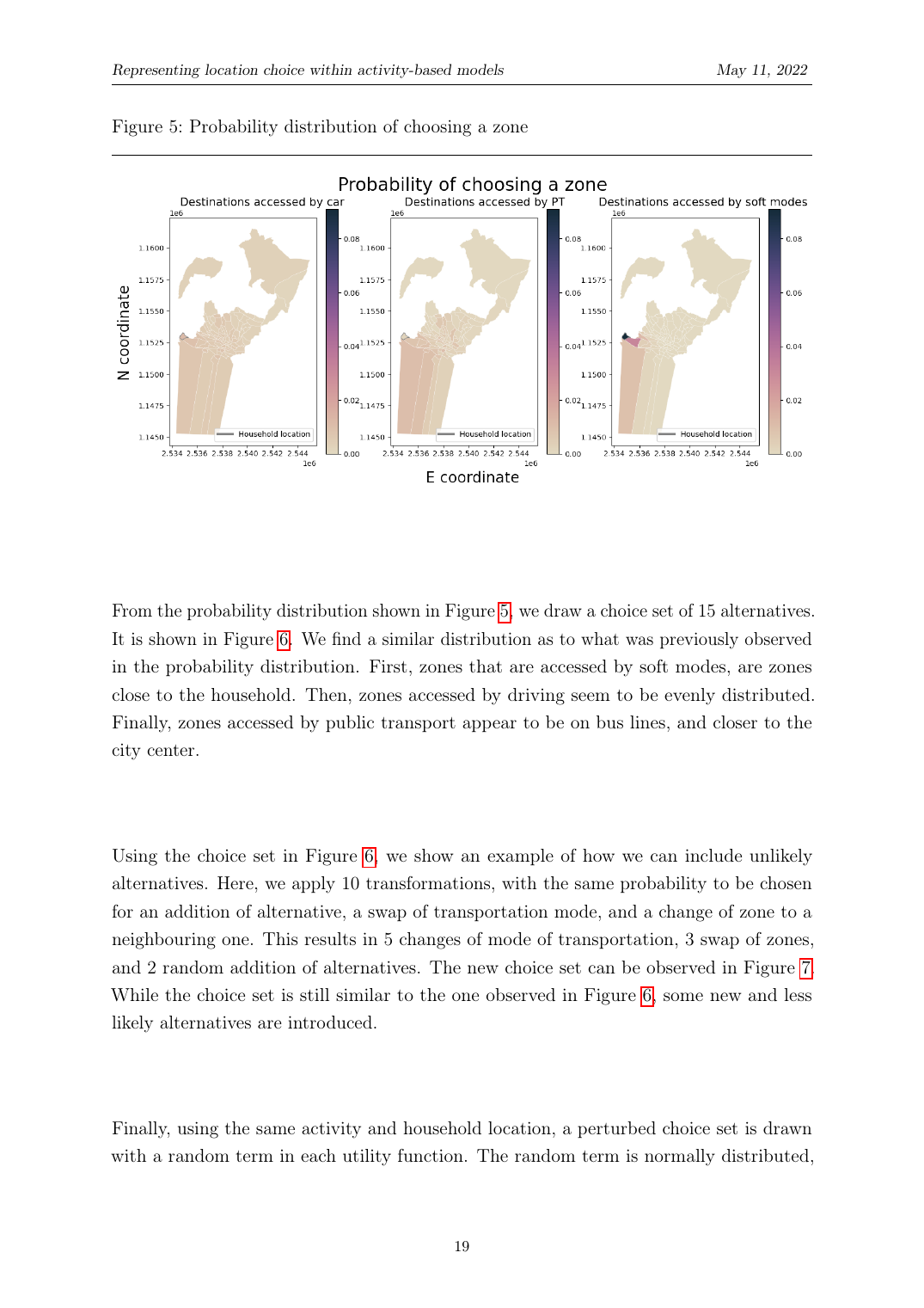
À partir du CNL estimé nous faisons de l'importance sampling de N alternatives par individu pour former un ensemble de choix Ĉ_n. La probabilité d'obtenir un ensemble de choix spécifique est en forme close, le produit des probabilités par tirage ajusté pour échantillonnage sans remise, ce qui signifie que nous pouvons calculer le terme de correction nécessaire pour une estimation de maximum de vraisemblance non biaisée en aval.
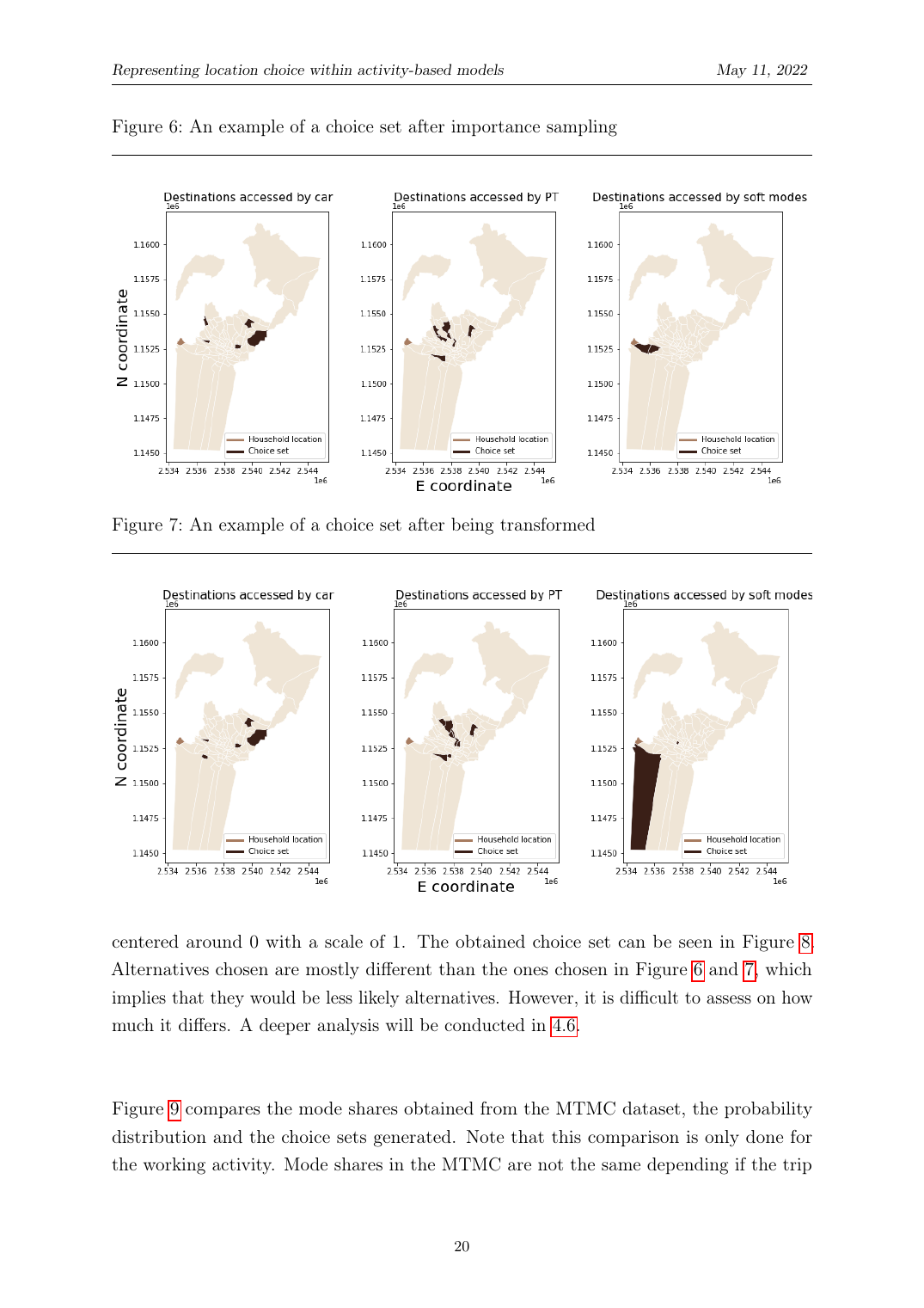
Nous perturbons l'ensemble issu de l'importance sampling avec trois opérateurs : (1) ajouter une alternative aléatoire absente de l'ensemble, (2) changer le mode d'une alternative pour un mode différent, (3) déplacer la destination d'une alternative vers une zone voisine. Chaque opérateur a une probabilité en forme close qui contribue à la P(Ĉ_n) globale utilisée dans le terme de correction de biais. Cela injecte les alternatives improbables nécessaires pour identifier pourquoi la choisie est préférée.
Nous avons validé sur le microrecensement Mobilité et Transports suisse 2015, restreint aux 3 536 trajets avec destinations à Lausanne. Le CNL ajuste significativement mieux qu'un simple logit sur les mêmes données (likelihood ratio 46,58, χ²(5, 95 %) = 11,07, nullité rejetée avec haute confiance).
Le résultat
Livrable : une méthodologie avec une probabilité d'échantillonnage en forme close P(Ĉ_n), ce qui permet à tout estimateur de modèle activity-based en aval d'ajouter un seul terme de correction multiplicatif et de retrouver des estimations de paramètres non biaisées. La génération d'ensembles de choix est désormais livrée comme le bloc correspondant du pipeline de modélisation activity-based OASIS à l'EPFL Transp-OR, présentée à STRC 2022.
Sur l'étude de cas Lausanne (88 zones × 3 modes, 3 536 trajets du microrecensement), le cross-nested logit ajuste significativement mieux qu'un simple logit (LR = 46,6 vs χ²(5, 95 %) = 11,07, nullité rejetée avec haute confiance), confirmant que le couplage mode/destination conjoint est réel et mérite d'être modélisé — pas une hypothèse que la génération précédente de filtres basés sur des règles pouvait capturer.
Plongée technique
Le modèle derrière le résultat.
Le modèle
Le cœur méthodologique a trois pièces qui s'emboîtent : une spécification cross-nested logit pour l'utilité mode-et-destination, une règle d'importance sampling qui tire des ensembles de choix depuis la distribution de probabilité CNL, et une étape de perturbation qui injecte des alternatives improbables tout en gardant la probabilité globale de tirage en forme close. La probabilité de tirage en forme close est la clé, c'est ce qui permet à l'estimateur du modèle activity-based en aval d'ajouter un terme de correction et de récupérer des estimations de paramètres non biaisées.
Utilité conjointe mode-et-destination. Pour l'individu n choisissant la zone z et le mode m : une constante spécifique à l'alternative ASC_m par mode ; un coefficient de temps de trajet spécifique au mode β^TIME_m × TT_zm ; un effet de type de zone (urbain/rural/intermédiaire) ; et un effet de densité dépendant de l'activité ρ^a_z = densité d'emplois, densité de population, ou somme, différent pour travail, éducation, loisirs, achats, autre.
Probabilité de choix cross-nested logit. Chaque alternative i appartient simultanément à deux nids (un nid mode et un nid de groupe géographique), avec degré d'appartenance α_ik ∈ [0, 1]. Les paramètres d'échelle µ_k > 1 capturent la corrélation au sein de chaque nid.
Probabilité d'importance sampling sans remise. La probabilité de tirer un ensemble de choix spécifique Ĉ_n de taille N est le produit de N probabilités par tirage, c'est en forme close, ce qui est tout l'intérêt : la MLE en aval connaît P_IS exactement et peut calculer le terme de correction de biais sans intégration Monte Carlo.
Probabilités des opérateurs de perturbation. ‘add' choisit une alternative aléatoire hors de l'ensemble ; ‘swap' choisit une alternative et change son mode ; ‘change' décale la zone d'une alternative vers un voisin aléatoire.
Probabilité de tirage globale après T perturbations. Le modélisateur choisit les trois probabilités de sélection d'opérateur et le nombre de perturbations T. La probabilité totale P(Ĉ_n) est le produit de la probabilité d'importance sampling et des probabilités par perturbation, toujours en forme close.
Log-vraisemblance corrigée pour l'estimation ABM en aval. Avec la probabilité d'inclusion par alternative connue, la MLE peut corriger le fait que nous estimons sur un ensemble échantillonné. Sans ce terme de correction, les paramètres sont biaisés.
Test de spécification : CNL vs logit simple. La structure cross-nested a 5 paramètres libres de plus. La statistique LR de 46,58 dépasse largement la valeur critique χ² à 95 %, la structure CNL ajuste significativement mieux.
La P(Ĉ_n) en forme close est la pièce porteuse de toute la construction. Une fois que vous l'avez, toute la machinerie de modélisation activity-based en aval fonctionne correctement, car la correction de biais vit dans un seul facteur multiplicatif. Le CNL au-dessus est le choix de modélisation qui rend l'interaction conjointe mode-destination explicite.
Benchmark
Estimation cross-nested logit sur le microrecensement suisse 2015 (3 536 trajets lausannois, 88 zones × 3 modes, biogeme 3.2.6). Valeurs : estimations de coefficients avec erreurs standard robustes.
| Paramètre | Valeur | Err. std robuste | Test t robuste | Valeur p robuste |
|---|---|---|---|---|
| ASC_car | −1,99 | 0,118 | −16,8 | ≈ 0 |
| ASC_pt | −1,73 | 0,190 | −9,12 | ≈ 0 |
| B_TIME_softmodes | −0,537 | 0,0124 | −43,3 | ≈ 0 |
| B_TIME_car | −0,457 | 0,0818 | −5,59 | 2,2e-08 |
| B_TIME_pt | −0,327 | 0,0589 | −5,55 | 2,9e-08 |
| B_JobD_WORK | +0,00335 | 0,00136 | +2,48 | 0,013 |
| B_PopD_EDUC | −0,0251 | 0,00576 | −4,36 | 1,3e-05 |
| B_PopD_LEIS | −0,0189 | 0,00291 | −6,51 | 7,3e-11 |
| B_JobD_PopD_SHOP | +0,00712 | 0,00334 | +2,13 | 0,033 |
| MU_CAR | 7,06 | 4,99 | 1,41 | 0,157 |
| MU_PT | 1,63 | 0,433 | 3,76 | 1,7e-04 |
| MU_CENTER | 1,66 | 0,118 | 14,1 | ≈ 0 |
| MU_EAST | 2,05 | 0,186 | 11,0 | ≈ 0 |
| MU_WEST | 1,98 | 0,177 | 11,2 | ≈ 0 |
Trois conclusions. Premièrement, les ASC pour la voiture (−1,99) et le transport public (−1,73) sont négatifs, les soft modes (marche/vélo) sont préférés en baseline, cohérent avec les courts trajets lausannois de 0,5–5 km. Deuxièmement, les coefficients de densité changent de signe selon l'activité : le travail préfère la forte densité d'emplois, les loisirs/éducation préfèrent la faible densité de population. Troisièmement, les paramètres de nid géographique (MU_CENTER, MU_EAST, MU_WEST) sont tous significativement > 1, confirmant une vraie corrélation spatiale. MU_CAR à 7,06 avec significativité marginale est un artefact de petit échantillon.
Tiré du dossier

Techniques
- Modèle cross-nested logit (CNL)
- Importance sampling pour ensembles de choix
- Distribution de probabilité conjointe mode/destination
- Demande de transport activity-based
- Correction de biais en estimation DCM
- Opérateurs de perturbation stochastique
Stack
- Python
- Biogeme 3.2.6
- Microrecensement suisse 2015
- Matrices de distance MATSim
Un problème de ce type ?