Gemeinsame Mode-und-Ziel-Choice-Sets, jetzt live in der OASIS-Pipeline der EPFL
Erste Methode, die die Mode/Ziel-Kopplung gemeinsam erfasst, mit einem geschlossen-formigen Bias-Korrekturterm, der in jeden aktivitätsbasierten-Modell-Schätzer einspielbar ist
Aktivitätsbasierte Verkehrsmodelle leben und sterben mit ihren Choice Sets. Nutze das Universum jedes möglichen Ziels und die Parameter-Schätzung kriecht. Nutze einen naiven Filter und du verzerrst das Modell. Nutze starre distanzbasierte Heuristiken und du erfasst die Mode-Ziel-Interaktion nicht.
Wir haben einen gemeinsamen stochastischen Choice-Set-Generierungsansatz mitverfasst: ein Cross-Nested-Logit auf beobachteten Mode-und-Ziel-Kombinationen schätzen, mit Importance Sampling aus der resultierenden Wahrscheinlichkeitsverteilung ziehen und das gezogene Set mit drei zufälligen Operatoren perturbieren, um unwahrscheinliche Alternativen einzuschleusen, was wettbewerbsbasierte Sets für die Simulation und eine kontrollierte Mischung wahrscheinlicher/unwahrscheinlicher Optionen für eine unverzerrte Parameterschätzung liefert.
Die Herausforderung
Über Jahrzehnte hinweg wurde Choice-Set-Generierung in der aktivitätsbasierten Modellierung als fester, oft willkürlicher Vorverarbeitungsschritt behandelt, typisch über regelbasierte Distanz- oder Zeitfilter (Hägerstrands Zeit-Raum-Prismen, Schönfelder-Axhausen-Aktivitäts-Ellipsen, Scherr et al.s Rubber-Banding). Das Ergebnis sind verzerrte Parameter-Schätzungen, geschwächte Simulationsrealität und keine Möglichkeit, die echte Kopplung zwischen Mode- und Ziel-Entscheidung zu erfassen (ein Auto gibt einem Ziele, die mit ÖV nicht erreichbar sind; bei Verkehr zur Spitzenstunde werden nähere Ziele attraktiver).
Die Herausforderung: eine Methode bauen, die Choice Sets erzeugt, die gleichzeitig für die Simulation (kompetitive Alternativen) und die Schätzung (kontrollierte Mischung wahrscheinlicher und unwahrscheinlicher Optionen) nützlich sind, und die Interaktion zwischen Mode und Ziel erfasst, nicht nur eines nach dem anderen. Mit 88 Zonen × 3 Modi auch in einer kleinen Fallstudie sind das 264 universelle Alternativen pro Person; für 8 000 Schweizer Zonen wären es 24 000.
Unser Vorgehen
Wir schätzen ein Cross-Nested Logit (CNL) auf beobachteten Mode-und-Ziel-Kombinationen aus einem Reisetagebuch. Die CNL-Struktur setzt jede Alternative gleichzeitig in zwei Nester: eines entsprechend ihrem Verkehrsmodus (Mode-Korrelation zwischen Alternativen, die auf gleichem Weg erreicht werden), eines entsprechend ihrer geographischen Gruppe (räumliche Korrelation zwischen nahe beieinander liegenden Zonen).
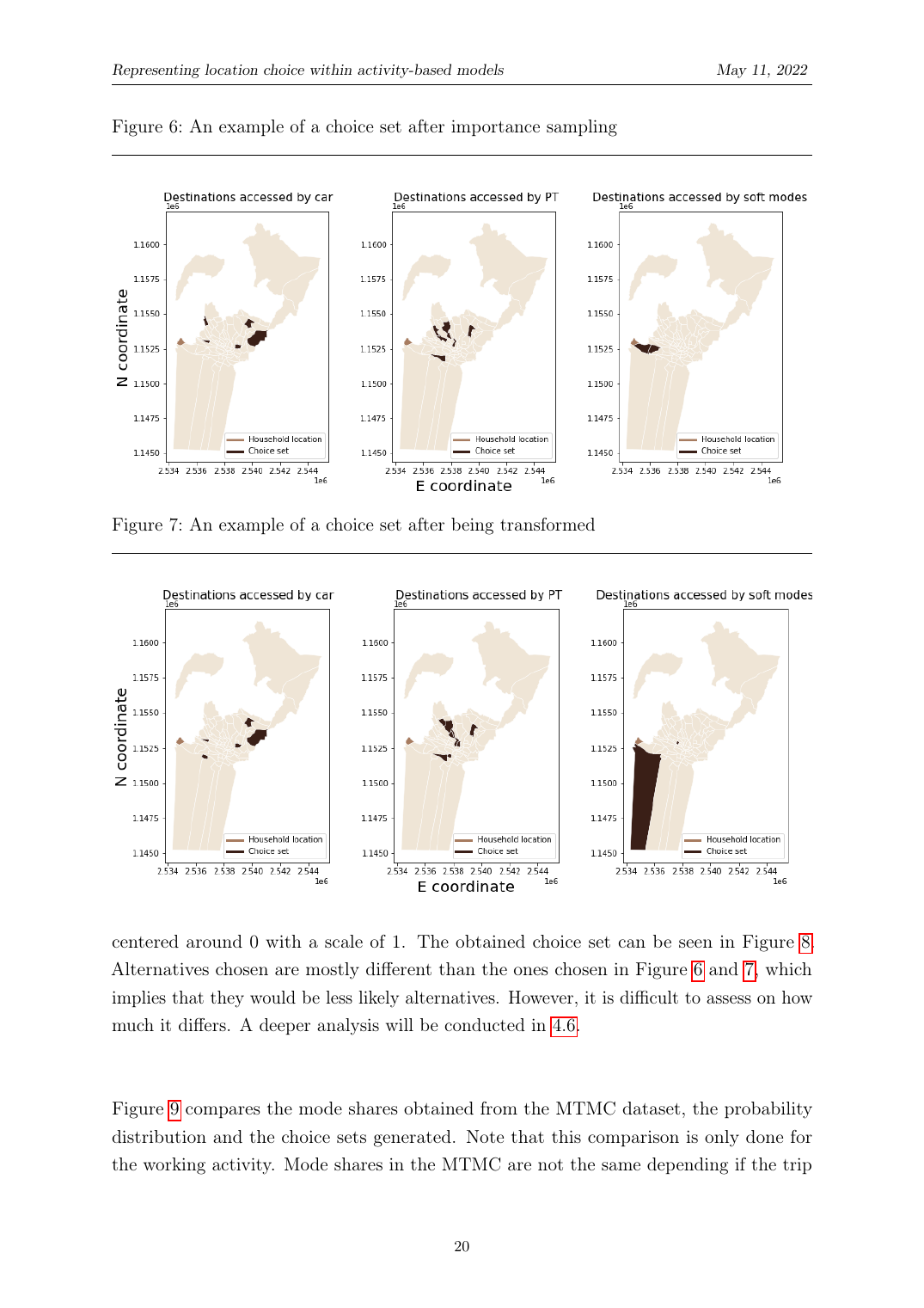
Aus dem geschätzten CNL nehmen wir N Alternativen per Importance Sampling, um ein Choice Set Ĉ_n pro Person zu bilden. Die Wahrscheinlichkeit, ein spezifisches Choice Set zu erhalten, ist geschlossen-formig, das Produkt der Per-Draw-Wahrscheinlichkeiten, korrigiert um Sampling ohne Zurücklegen, was bedeutet, dass wir den Korrekturterm berechnen können, der für eine unverzerrte Maximum-Likelihood-Schätzung nachgelagert nötig ist.
Wir perturbieren das Importance-Sample-Set mit drei Operatoren: (1) eine zufällige Alternative hinzufügen, die nicht im Set ist, (2) den Modus einer Alternative auf einen anderen Modus tauschen, (3) das Ziel einer Alternative auf eine Nachbarzone verschieben. Jeder Operator hat eine geschlossen-formige Wahrscheinlichkeit, die in die Gesamt-P(Ĉ_n) für den Bias-Korrekturterm einfliesst. Das schleust die unwahrscheinlichen Alternativen ein, die nötig sind, um zu identifizieren, warum die gewählte bevorzugt wird.
Wir haben auf dem Schweizer Mobilitäts- und Verkehrs-Mikrozensus 2015 validiert, eingeschränkt auf 3 536 Trips mit Zielen in Lausanne. Das CNL passt signifikant besser als ein simples Logit auf denselben Daten (Likelihood Ratio 46,58, χ²(5, 95 %) = 11,07, Nullhypothese mit hoher Konfidenz abgelehnt).
Das Ergebnis
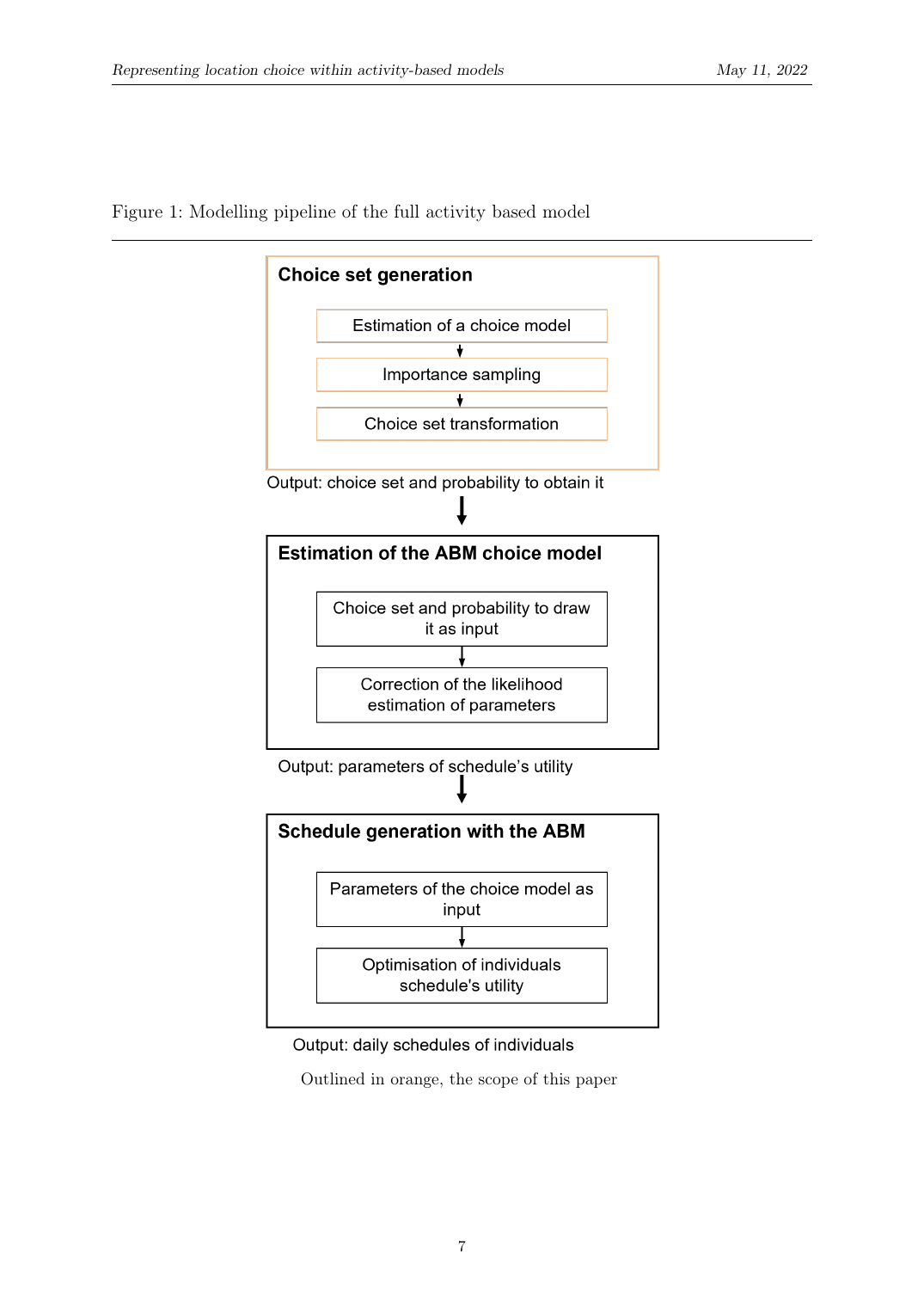
Deliverable: eine Methodik mit geschlossen-formiger Sampling-Wahrscheinlichkeit P(Ĉ_n), die jedem nachgelagerten aktivitätsbasierten-Modell-Schätzer erlaubt, einen einzigen multiplikativen Korrekturterm hinzuzufügen und unverzerrte Parameter-Schätzungen zu erhalten. Die Choice-Set-Generierung ist heute der entsprechende Baustein der OASIS-aktivitätsbasierten-Modellierungs-Pipeline an der EPFL Transp-OR und wurde an der STRC 2022 vorgestellt.
Auf der Lausanne-Fallstudie (88 Zonen × 3 Modi, 3’536 Mikrozensus-Trips) passt das Cross-Nested-Logit signifikant besser als ein simples Logit (LR = 46,6 vs. χ²(5, 95 %) = 11,07, Nullhypothese mit hoher Konfidenz abgelehnt) und bestätigt, dass die gemeinsame Mode/Ziel-Kopplung real und modellierwürdig ist — nicht eine Annahme, die die vorige Generation regelbasierter Filter erfassen konnte.
Technischer Deep Dive
Das Modell hinter dem Ergebnis.
Das Modell
Der methodische Kern hat drei Stücke, die zusammenpassen: eine Cross-Nested-Logit-Spezifikation für Mode-und-Ziel-Nutzen, eine Importance-Sampling-Regel, die Choice Sets aus der CNL-Wahrscheinlichkeitsverteilung zieht, und einen Perturbations-Schritt, der unwahrscheinliche Alternativen einschleust, während die Gesamt-Sampling-Wahrscheinlichkeit geschlossen-formig bleibt. Die geschlossen-formige Sampling-Wahrscheinlichkeit ist der Schlüssel, sie erlaubt dem nachgelagerten aktivitätsbasierten Schätzer, einen Korrekturterm hinzuzufügen und unverzerrte Parameterschätzungen zu erhalten.
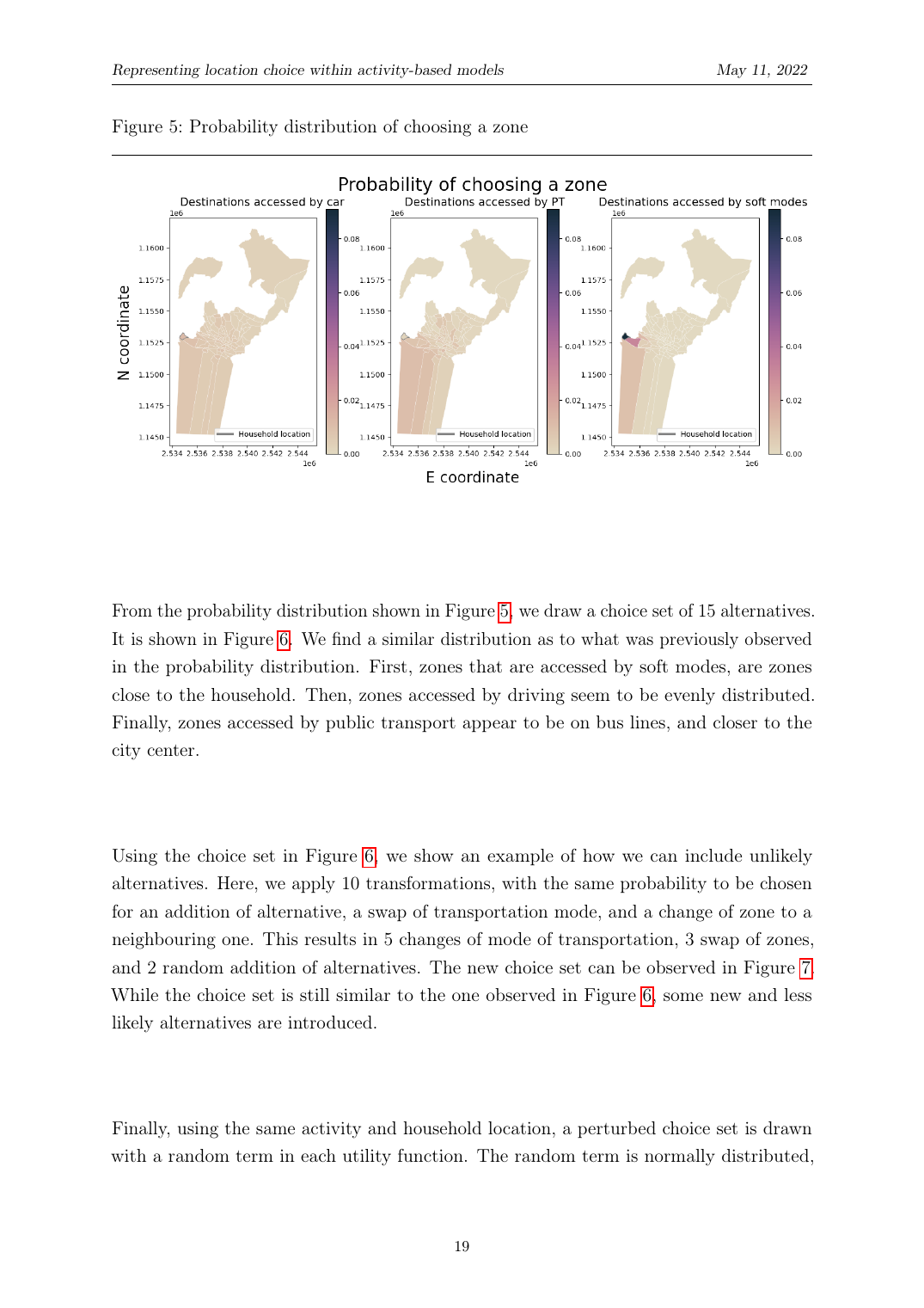
Gemeinsame Mode-und-Ziel-Nutzenfunktion. Für Person n, die Zone z und Modus m wählt: eine alternative-spezifische Konstante ASC_m pro Modus; ein modusspezifischer Reisezeitkoeffizient β^TIME_m × TT_zm; ein Zonen-Typ-Effekt (urban/ländlich/intermediär); und ein aktivitätsabhängiger Dichte-Effekt ρ^a_z = Job-Dichte, Bevölkerungsdichte oder eine Summe, unterschiedlich für Arbeit, Bildung, Freizeit, Einkauf, anderes. Die Aktivitäts-Dichte-Koeffizienten erlauben dem Modell, Aussagen wie ‘eine Arbeitsaktivität bevorzugt hohe-Job-Dichte-Zonen’ oder ‘eine Bildungsaktivität bevorzugt niedrige-Bevölkerungsdichte-Zonen’ zu treffen, ohne die Mode-Ziel-Kopplung zu verlieren.
Cross-Nested-Logit-Wahrscheinlichkeit. Jede Alternative i gehört gleichzeitig zwei Nestern an (einem Mode-Nest und einem geographischen Nest), mit Mitgliedschaftsgrad α_ik ∈ [0, 1]. Die Skalenparameter µ_k > 1 erfassen die Korrelation innerhalb jedes Nests, empirisch geschätzt von 1,63 (ÖV) bis 7,06 (Auto) auf den Lausanne-Daten. Das CNL passt signifikant besser als ein simples Logit (LR-Test 46,58 vs. χ²(5) = 11,07).
Importance-Sampling-Wahrscheinlichkeit ohne Zurücklegen. Die Wahrscheinlichkeit, ein spezifisches Choice Set Ĉ_n der Grösse N zu ziehen, ist das Produkt von N Per-Draw-Wahrscheinlichkeiten, Zähler ist die CNL-Choice-Wahrscheinlichkeit der j-ten Alternative, Nenner renormalisiert, nachdem jeder vorherige Draw aus dem Träger entfernt ist. Das ist geschlossen-formig, was der ganze Punkt ist: Die nachgelagerte MLE kennt P_IS exakt und kann den Bias-Korrekturterm ohne Monte-Carlo-Integration berechnen.
Perturbations-Operator-Wahrscheinlichkeiten. Nach dem Importance Sampling schleusen drei Operatoren unwahrscheinliche Alternativen ein: ‘add’ wählt eine zufällige Alternative ausserhalb des Sets (uniform über die ZM − N Alternativen ausserhalb von Ĉ_n); ‘swap’ wählt eine Alternative und tauscht ihren Modus (1/N für die Alternative × 1/(M−1) für einen anderen Modus); ‘change’ verschiebt die Zone einer Alternative auf einen zufälligen Nachbarn (1/N × 1/Nei_j, wobei Nei_j die Anzahl geographischer Nachbarn ist). Jeder Operator ist ungültig, wenn die resultierende Alternative bereits im Set ist, per Rejection behandelt.
Gesamte Sampling-Wahrscheinlichkeit nach T Perturbationen. Der Modellierer wählt die drei Operator-Auswahl-Wahrscheinlichkeiten (p_add, p_swap, p_change summieren sich zu 1) und die Anzahl Perturbationen T. Die Gesamtwahrscheinlichkeit P(Ĉ_n) ist das Produkt aus Importance-Sampling-Wahrscheinlichkeit und Per-Perturbations-Wahrscheinlichkeiten, weiterhin geschlossen-formig, was diese ganze Konstruktion in der nachgelagerten Maximum-Likelihood-Schätzung nutzbar macht.
Korrigierte Log-Likelihood für nachgelagerte ABM-Schätzung. Mit der Per-Alternative-Einschlusswahrscheinlichkeit P(j ∈ Ĉ_n) bekannt (berechenbar aus P(Ĉ_n)), kann die MLE des aktivitätsbasierten Modells korrigieren, dass wir auf einem gezogenen Choice Set statt dem Universum schätzen. Ohne diesen Korrekturterm sind die Parameter verzerrt, Alternativen, die der Sampler überrepräsentiert, sehen attraktiver aus, als sie wirklich sind. McFaddens klassisches Resultat verallgemeinert sich auf diesen Fall, weil P_IS geschlossen-formig ist.
Spezifikationstest: CNL vs. simples Logit. Die Cross-Nested-Struktur hat 5 mehr freie Parameter als die auf Logit eingeschränkte Version (alle α auf 0/1 und alle µ auf 1 gesetzt). Die Likelihood-Ratio-Statistik 46,58 übersteigt den χ²-Kritikwert auf 95 % Konfidenz deutlich, die CNL-Struktur passt signifikant besser. Konkret: Es gibt echte Mode-Korrelation und echte räumliche Korrelation in den Daten, und ihre Modellierung verbessert den Fit genug, um die zusätzlichen Parameter zu rechtfertigen.
Die geschlossen-formige P(Ĉ_n) ist das tragende Stück der ganzen Konstruktion. Hat man sie einmal, funktioniert die ganze nachgelagerte aktivitätsbasierte Modellierungs-Maschinerie, Likelihood-basierte Schätzung, Simulation unter den geschätzten Parametern, Importance-Sample-Prognose, korrekt, ohne dass man verfolgen muss, welche Alternativen der Sampler gesehen hat oder nicht, weil die Bias-Korrektur in einem einzigen multiplikativen Faktor lebt. Das CNL darüber ist die Modellwahl, die die gemeinsame Mode-und-Ziel-Interaktion explizit macht; ohne sie (mit einem simplen Logit) würde die IIA-Eigenschaft unrealistische Substitutionsmuster erzwingen, sobald man Alternativen hinzufügt oder entfernt.
Benchmark
Cross-Nested-Logit-Schätzung auf dem Schweizer Mobilitäts- und Verkehrs-Mikrozensus 2015 (3 536 Lausanne-Trips, 88 Zonen × 3 Modi, biogeme 3.2.6). Berichtete Werte sind Koeffizientenschätzungen mit robusten Standardfehlern. ASC = alternative-spezifische Konstante; B_TIME = Reisezeitkoeffizient pro Modus; B_<x>_<Aktivität> = Dichte-Effekt für Aktivitätstyp. Die 5 µ-Parameter sind die Nest-Skalenkoeffizienten (müssen > 1 sein, um sinnvoll zu sein; > 1 bedeutet Within-Nest-Korrelation).
| Parameter | Wert | Robuster Std-Fehler | Robuster t-Test | Robuster p-Wert |
|---|---|---|---|---|
| ASC_car | −1,99 | 0,118 | −16,8 | ≈ 0 |
| ASC_pt | −1,73 | 0,190 | −9,12 | ≈ 0 |
| B_TIME_softmodes | −0,537 | 0,0124 | −43,3 | ≈ 0 |
| B_TIME_car | −0,457 | 0,0818 | −5,59 | 2,2e-08 |
| B_TIME_pt | −0,327 | 0,0589 | −5,55 | 2,9e-08 |
| B_JobD_WORK | +0,00335 | 0,00136 | +2,48 | 0,013 |
| B_PopD_EDUC | −0,0251 | 0,00576 | −4,36 | 1,3e-05 |
| B_PopD_LEIS | −0,0189 | 0,00291 | −6,51 | 7,3e-11 |
| B_JobD_PopD_SHOP | +0,00712 | 0,00334 | +2,13 | 0,033 |
| MU_CAR (Nest-Skalierung) | 7,06 | 4,99 | 1,41 | 0,157 |
| MU_PT (Nest-Skalierung) | 1,63 | 0,433 | 3,76 | 1,7e-04 |
| MU_CENTER (Geo-Nest) | 1,66 | 0,118 | 14,1 | ≈ 0 |
| MU_EAST (Geo-Nest) | 2,05 | 0,186 | 11,0 | ≈ 0 |
| MU_WEST (Geo-Nest) | 1,98 | 0,177 | 11,2 | ≈ 0 |
Drei inhaltliche Befunde. Erstens: Die ASCs für Auto (−1,99) und ÖV (−1,73) sind beide negativ, was bedeutet, dass soft modes (Gehen/Velo) als Baseline bevorzugt werden, wenn Reisezeit und andere Faktoren null sind. Das passt zu den kurzen Trips eines 0,5–5 km-Lausanne-Datensatzes. Zweitens: Die Aktivitäts-Dichte-Koeffizienten flippen das Vorzeichen je nach Aktivität: Arbeitsaktivitäten bevorzugen Zonen mit hoher Job-Dichte (+0,0034 / Job·m^−2), Freizeit- und Bildungsaktivitäten bevorzugen Zonen mit niedriger Bevölkerungsdichte (−0,019 bis −0,025 / Person·m^−2). Genau dieses Substitutionsmuster kann ein simples Logit nicht erfassen, verschiedene Aktivitäten ziehen in verschiedene Stadtteile. Drittens: Die geographischen Nest-Parameter (MU_CENTER = 1,66, MU_EAST = 2,05, MU_WEST = 1,98) sind alle signifikant über 1, was echte räumliche Korrelation bestätigt: Zonen innerhalb derselben Gruppe teilen unbeobachtete Eigenschaften, die Individuen kollektiv zu ihnen ziehen. MU_CAR mit hoher Schätzung (7,06) bei marginaler Signifikanz ist ein Small-Sample-Artefakt (nur 1 316 Auto-Trips mit 276 Alternativen je).
Aus den Unterlagen

Techniken
- Cross-Nested-Logit-Modell (CNL)
- Importance Sampling für Choice Sets
- Gemeinsame Mode/Ziel-Wahrscheinlichkeitsverteilung
- Aktivitätsbasierte Verkehrsnachfrage
- Bias-Korrektur in DCM-Schätzung
- Stochastische Perturbations-Operatoren
Stack
- Python
- Biogeme 3.2.6
- Schweizer Mikrozensus 2015
- MATSim-Distanz-Matrizen
Ein Problem wie dieses?