Quand la programmation par contraintes bat le MILP
Analyse comparative pour la planification activity-based
Quand tout le monde utilise du MILP, on change parfois de paradigme. L'équipe a pris le MILP publié pour la planification activity-based de Pougala, Hillel et Bierlaire (2021), l'a reconstruit en programmation par contraintes avec le CP-SAT d'OR-Tools, et a prouvé que la CP idiomatique, implications comme contraintes natives, contraintes globales ELEMENT, propagation au lieu de branch-and-bound, surpasse le MILP de 750× sur les instances à 5 activités.
La leçon plus profonde, qui est la valeur que nous apportons aux clients : tous les problèmes d'optimisation ne méritent pas le même marteau. Un résultat négatif aussi, les variables d'intervalle et NO_OVERLAP, souvent vantées comme la fonctionnalité phare de CP-SAT pour la planification, *n'aident pas* ici, car la contrainte de cohérence temporelle fige déjà la séquence des activités.
Le défi
La planification d'activités sous maximisation d'utilité (Pougala et al. 2021) est l'approche économétrique moderne de la prévision de demande de transport, elle capture l'arbitrage conjoint entre participation aux activités, timing, durée, lieu et mode que les anciens ABM séquentiels et basés sur des règles manquent. Le prix est un MILP brutal : le temps de simulation à population complète passe à l'échelle d'environ un ordre de grandeur par activité ajoutée par individu, ce qui est intractable quand il faut simuler des millions d'agents.
La question naturelle, un paradigme de solveur différent serait-il mieux adapté au problème ?, restait sans réponse dans la littérature pour la planification activity-based en particulier. Les traductions naïves entre paradigmes aident rarement ; la vraie question est si la CP *idiomatique*, utilisant les contraintes globales et les moteurs de propagation qui exploitent la structure combinatoire discrète, peut surpasser un MILP raffiné.
Notre démarche
Nous avons co-encadré trois variantes CP du MILP de Pougala et al. (2021), toutes implémentées dans le solveur CP-SAT de Google OR-Tools et benchmarkées tête-à-tête contre le MILP original. Le temps est discrétisé dans les versions CP (la CP requiert des variables de décision entières) tandis que le MILP garde un temps continu.
Variante 1, Traduction CP directe : un port quasi mécanique du MILP. Même schéma de duplication d'activité (une variable de décision par triplet activité × mode × emplacement, avec indicateurs de séquence z_ab et α_a^car pour la cohérence de mode de tour). Implications écrites comme contraintes CP natives au lieu d'être linéarisées avec big-M. Utilisée comme baseline ‘que fait la CP gratuitement ?'.
Variante 2, CP indexé : remplace la duplication d'activité par de l'indexation de tableau. Mode m_a et emplacement l_a deviennent des variables de décision par activité (au lieu d'avoir une copie séparée de chaque activité pour chaque combinaison) ; la recherche du temps de trajet se fait via la contrainte globale ELEMENT sur un tableau aplati |M| × |L|² de temps de trajet D. La cohérence de mode devient une implication propre en deux lignes. C'est la version qui gagne.
Variante 3, CP intervalle : ajoute les variables d'intervalle de CP-SAT I(x_a, Θ_a, y_a, ω_a) avec NO_OVERLAP sur toutes les activités. En théorie cela devrait aider, la planification par intervalles est un cas d'usage vitrine de CP-SAT. En pratique non, car la contrainte de cohérence temporelle existante (z_ab ⟹ x_a + τ_a + t_ab = x_b) fige déjà les activités en séquence, laissant NO_OVERLAP comme surcoût redondant.
Toutes les variantes ont été benchmarkées sur des jeux d'activités générés aléatoirement de RANDOM-2 à RANDOM-5 (2 à 5 activités distinctes, avec dawn et dusk fixés). 100 itérations par paire (modèle, instance), paramètres d'erreur frais à chaque itération, avec intervalles de confiance bootstrap à 95 % sur le temps moyen.
Le résultat
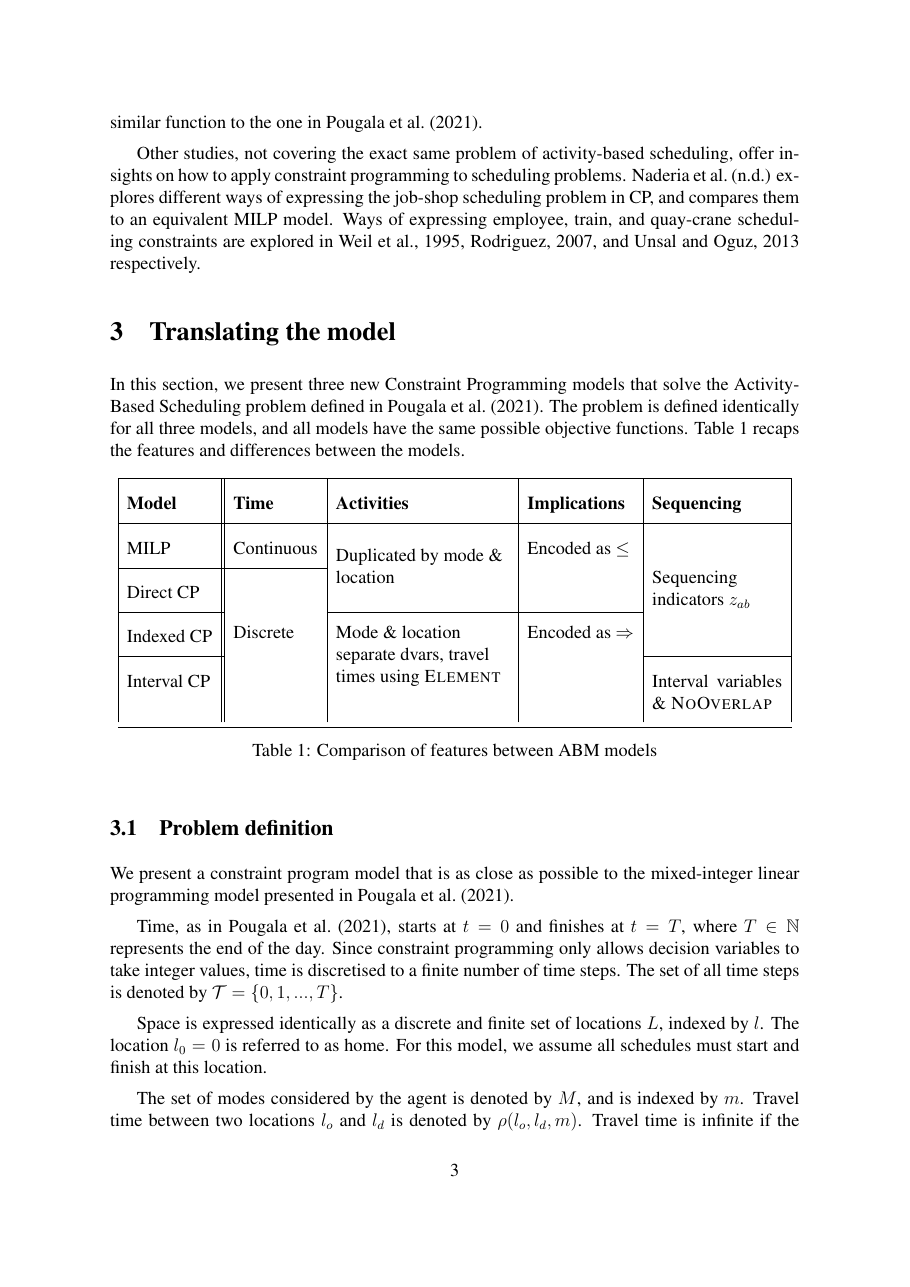
La variante CP indexé surpasse la baseline MILP d'environ un ordre de grandeur sur 2 activités et de presque trois ordres de grandeur sur 5 activités. À 5 activités : MILP 67,6 s vs CP indexé 0,09 s, accélération 750×. La traduction CP directe seule achète 20× à 5 activités, démontrant que même un changement de paradigme mécanique paie.
Le livrable est plus qu'un chiffre : c'est une méthodologie pour choisir le bon paradigme par classe de problème, et un résultat négatif clair (les variables d'intervalle n'aident pas) qui empêche de sur-vendre les fonctionnalités d'intervalle de CP-SAT à l'avenir.
Plongée technique
Le modèle derrière le résultat.
Le modèle
Le problème de Pougala et al. (2021) génère un emploi du temps quotidien : choisir quelles activités faire, dans quel ordre, à quelle heure de début, pour combien de temps, à quel endroit, avec quel mode, pour maximiser une utilité qui pénalise les écarts aux préférences. Les quatre variantes encodent le même problème ; les différences sont dans l'expression de la duplication d'activité et de la logique d'intervalle.
Objectif d'utilité partagé. Les termes V sont des pénalités déterministes (timing, durée, trajet) ; les termes U sont des erreurs Gumbel(0, 1). Les quatre variantes CP et le MILP optimisent le même objectif.
Somme journalière et séquencement. L'implication z_ab ⟹ (x_a + τ_a + ρ = x_b) propage l'information d'heure de début. En CP c'est une implication native que le propagateur gère directement, c'est là qu'une part significative de l'accélération vient.
Traduction directe : garder la duplication d'activité du MILP. Chaque combinaison (lieu, mode) est une variable séparée. La CP directe tourne 20× plus vite que le MILP à 5 activités juste grâce à la meilleure gestion des implications par CP-SAT.
Reformulation indexée : arrêter de dupliquer, commencer à indexer. Mode et lieu deviennent des variables par activité ; ELEMENT impose t_ab = D[i_ab]. C'est le changement structurel qui achète l'ordre de grandeur supplémentaire.
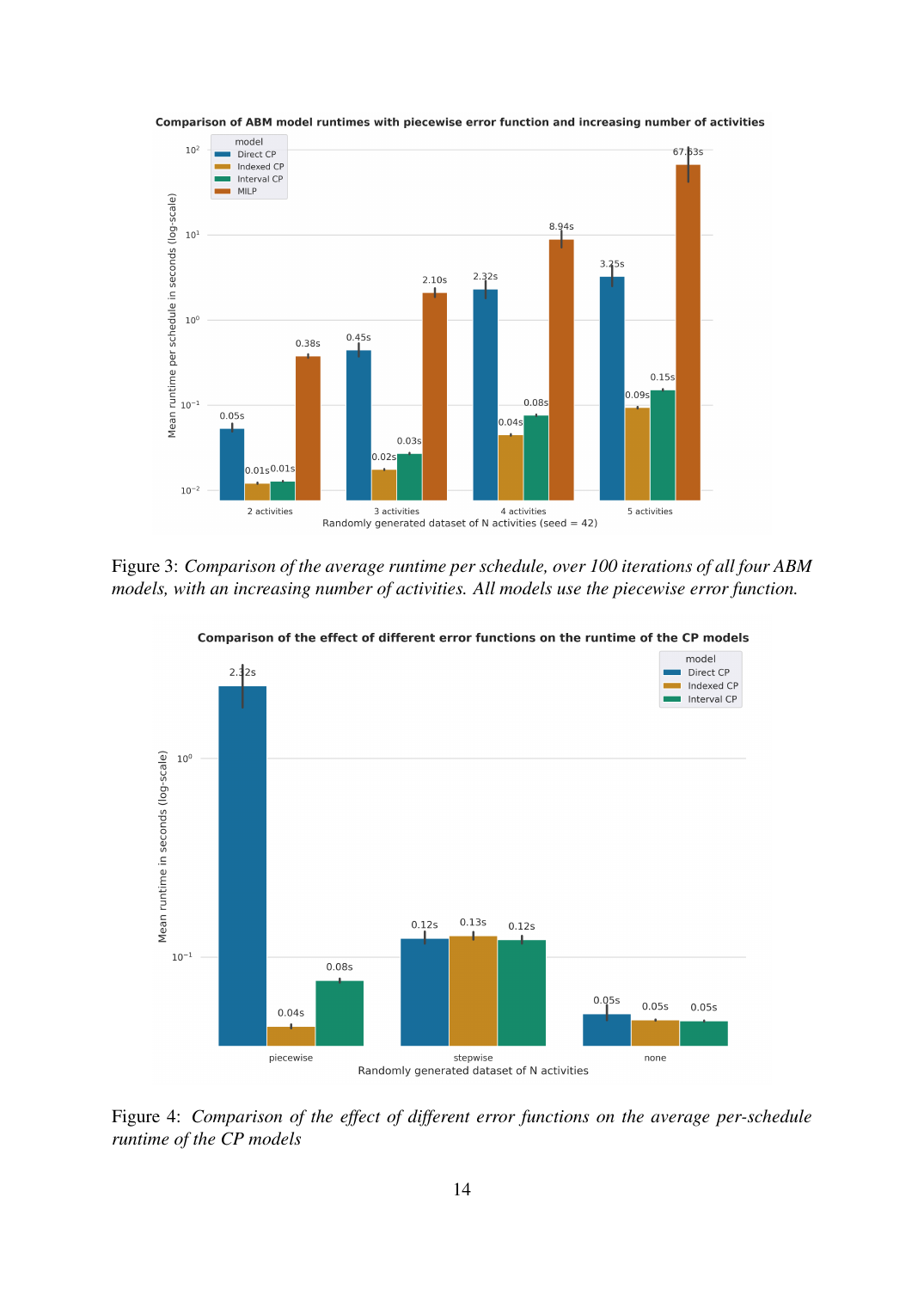
Variables d'intervalle avec NO_OVERLAP. Le résultat négatif : 1,5–2× plus lent que la version indexée, car l'implication existante de cohérence temporelle fige déjà la séquence, rendant NO_OVERLAP redondant.
Mise à l'échelle. MILP croît ~10× par activité (0,38 s → 67,6 s de N=2 à N=5). Le CP indexé croît seulement d'un facteur 9 sur toute la plage (0,01 s → 0,09 s), donnant 750× à N=5.
Le résultat phare est l'accélération 750×, mais le résultat *intéressant* est le résultat négatif sur les variables d'intervalle. CP-SAT est commercialisé pour intervalle+NO_OVERLAP, et pour le job-shop scheduling c'est valide, mais ici l'implication existante fait déjà le travail, donc la couche intervalle est pur overhead. Trois leçons : (1) le choix de paradigme compte plus que le réglage de paramètres, (2) les réécritures idiomatiques battent les traductions directes d'un autre ordre de grandeur, (3) les fonctionnalités tape-à-l'œil ne sont pas gratuites.
Benchmark
Temps moyen de résolution par emploi du temps sur jeux d'activités générés aléatoirement (RANDOM-2 à RANDOM-5), 100 itérations par paire, fonction d'erreur par morceaux. Temps en secondes.
| # Activités | MILP | Direct CP | Indexed CP | Interval CP | Accél. Indexed / MILP |
|---|---|---|---|---|---|
| 2 | 0,38 s | 0,05 s | 0,01 s | 0,01 s | 38× |
| 3 | 2,10 s | 0,45 s | 0,02 s | 0,03 s | 105× |
| 4 | 8,94 s | 2,32 s | 0,04 s | 0,08 s | 224× |
| 5 | 67,6 s | 3,25 s | 0,09 s | 0,15 s | 751× |
Le MILP passe à l'échelle ~10× par activité, explosion de branch-and-bound de manuel. La traduction CP directe se stabilise après 3 activités. Le CP indexé atteint une mise à l'échelle quasi plate. Le CP intervalle est systématiquement 1,5–2× plus lent que l'indexé, le résultat négatif. L'écart inter-datasets s'élargit vite : 38× sur la plus petite à 751× sur la plus grande. Sur la complexité d'objectif, la fonction d'erreur par morceaux expose le plus grand écart interne CP ; avec fonction nulle/par paliers toutes les variantes finissent en ~0,05–0,12 s, l'avantage du CP indexé ne se matérialise que sous des formes d'objectif réalistes.
Tiré du dossier

![Section 3.4, la reformulation indexée. Tableau D aplati à |M||L|² + 1 ; index i_ab calculé depuis m_a, l_a, l_b ; ELEMENT(i_ab, D, t_ab) impose t_ab = D[i_ab]. C'est le changement structurel qui achète un ordre de grandeur supplémentaire. La cohérence de mode devient une implication propre en deux lignes.](/figures/comparative/p-10.png)
Techniques
- Programmation par contraintes avec CP-SAT
- Programmation linéaire mixte (baseline MILP)
- Contrainte globale ELEMENT
- Implications comme objets de première classe
- Variables d'intervalle optionnelles + NO_OVERLAP
- Discrétisation temporelle pour compatibilité CP
Stack
- Python
- Google OR-Tools CP-SAT
- CPLEX (baseline MILP)
- MILP Pougala et al. 2021
Un problème de ce type ?