Wenn Constraint Programming MILP schlägt
Vergleichsanalyse für aktivitätsbasiertes Scheduling
Wenn alle MILP nutzen, wechselt man manchmal das Paradigma. Das Team nahm das publizierte MILP für aktivitätsbasiertes Scheduling von Pougala, Hillel und Bierlaire (2021), baute es in Constraint Programming mit dem CP-SAT-Solver von OR-Tools nach und zeigte, dass idiomatisches CP, Implikationen als native Constraints, ELEMENT-globale-Constraints, Propagation statt Branch-and-Bound, das MILP auf 5-Aktivitäts-Instanzen um 750× schlägt.
Die tiefere Lektion, die der Wert für Klienten ist: Nicht jedes Optimierungsproblem verdient denselben Hammer. Auch ein negativer Befund: Intervall-Variablen und NO_OVERLAP, oft als Killer-Feature von CP-SAT für Scheduling beworben, *helfen* hier *nicht*, weil die Zeitkonsistenz-Constraint die Aktivitätssequenz bereits festnagelt.
Die Herausforderung
Aktivitätsbasiertes Scheduling unter Nutzenmaximierung (Pougala et al. 2021) ist der moderne ökonometrische Ansatz für Verkehrsnachfrage-Prognose, er erfasst den gemeinsamen Trade-off über Aktivitäts-Teilnahme, Zeit, Dauer, Standort und Modus, den ältere sequentielle regelbasierte ABMs verfehlen. Der Preis ist ein brutales MILP: Voll-Bevölkerungs-Simulationszeit skaliert um etwa eine Grössenordnung pro hinzugefügter Aktivität pro Person, was nicht funktioniert, wenn man Millionen Agenten simulieren muss.
Die naheliegende Frage, würde ein anderes Solver-Paradigma besser zum Problem passen?, war in der Literatur für aktivitätsbasiertes Scheduling unbeantwortet. Naive Übersetzungen zwischen Paradigmen helfen selten; die echte Frage ist, ob *idiomatisches* CP, mit globalen Constraints und Propagations-Engines, die die diskrete kombinatorische Struktur ausnutzen, ein verfeinertes MILP übertreffen kann.
Unser Vorgehen
Wir haben drei CP-Varianten des MILP von Pougala et al. (2021) mitbetreut, alle im CP-SAT-Solver von Google OR-Tools implementiert und Kopf-an-Kopf gegen das Original-MILP gebenchmarkt. Die Zeit ist in den CP-Versionen diskretisiert (CP verlangt ganzzahlige Entscheidungsvariablen), während das MILP kontinuierliche Zeit behält.
Variante 1, Direkte CP-Übersetzung: ein nahezu mechanischer Port des MILP. Gleiches Aktivitätsduplikat-Schema (eine Entscheidungsvariable pro Aktivität × Modus × Standort-Tripel, mit Sequenzindikatoren z_ab und α_a^car für Tour-Modus-Konsistenz). Implikationen als native CP-Constraints geschrieben, nicht als Big-M-Linearisierungen. Genutzt als Baseline ‘was bringt CP gratis?’.
Variante 2, Indexiertes CP: ersetzt die Aktivitätsduplikation durch Array-Indexierung. Modus m_a und Standort l_a werden zu Entscheidungsvariablen pro Aktivität (statt einer separaten Kopie jeder Aktivität für jede Kombination); die Reisezeit-Tabelle wird über die ELEMENT-globale-Constraint auf einer flachen |M| × |L|²-Reisezeit-Tabelle D abgefragt. Modus-Konsistenz wird zu einer sauberen Zwei-Zeilen-Implikation. Das ist die Version, die gewinnt.
Variante 3, Intervall-CP: fügt CP-SATs Intervall-Variablen I(x_a, Θ_a, y_a, ω_a) mit NO_OVERLAP über alle Aktivitäten hinzu. Theoretisch sollte das helfen, Intervall-Scheduling ist ein CP-SAT-Vorzeige-Use-Case. In der Praxis tut es das nicht, weil die bestehende Zeitkonsistenz-Constraint (z_ab ⟹ x_a + τ_a + t_ab = x_b) Aktivitäten bereits in Sequenz pinnt und NO_OVERLAP redundanter Overhead wird.
Alle Varianten wurden auf zufällig generierten Aktivitäts-Sets von RANDOM-2 bis RANDOM-5 gebenchmarkt (2 bis 5 unterschiedliche Aktivitäten, mit dawn und dusk fest). 100 Iterationen pro (Modell, Instanz)-Paar, frische Fehlerparameter jedes Mal, mit Bootstrap-95-%-Konfidenzintervallen auf der mittleren Laufzeit.
Das Ergebnis
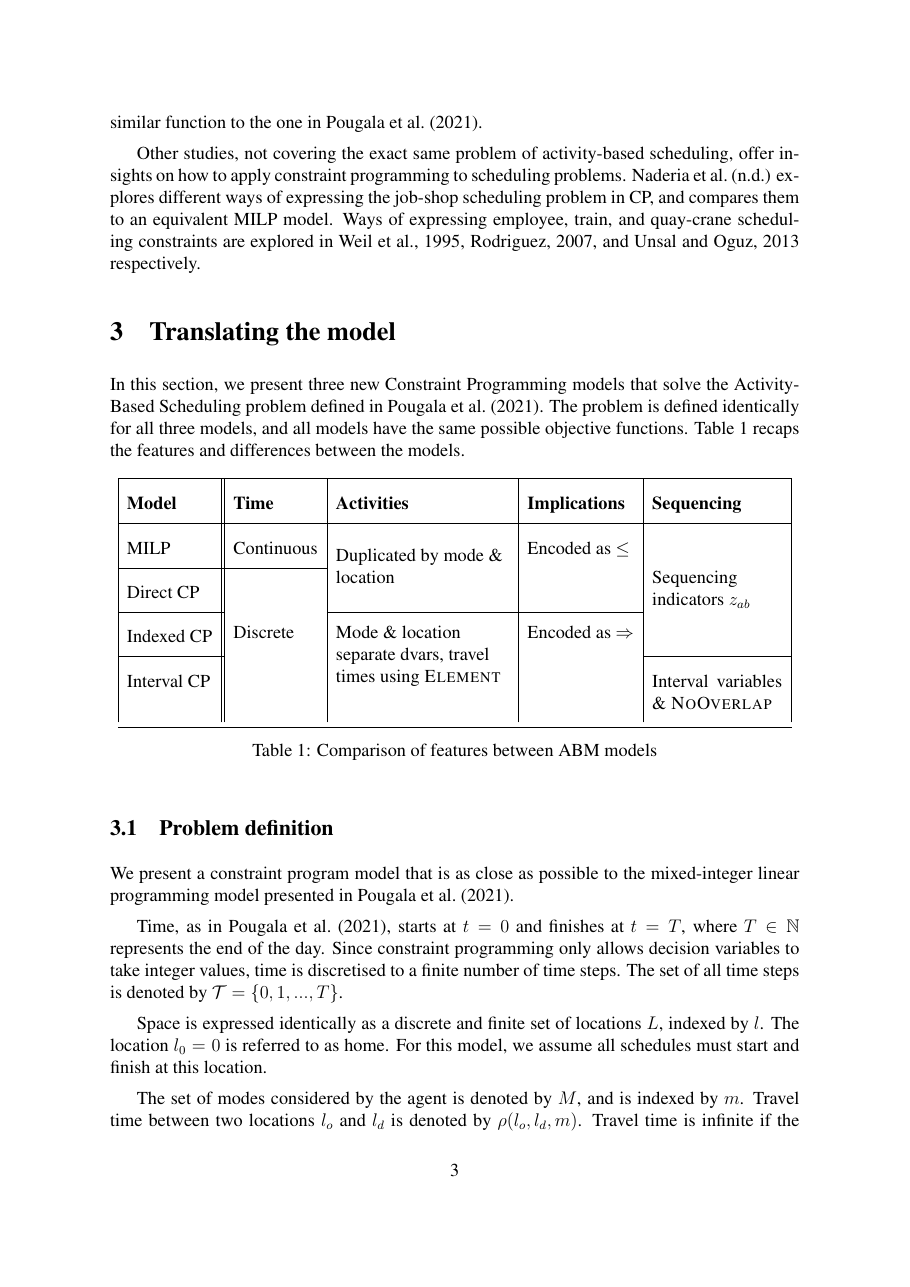
Die indexierte CP-Variante übertrifft das MILP-Baseline um etwa eine Grössenordnung auf 2-Aktivitäts-Instanzen und um fast drei Grössenordnungen auf 5-Aktivitäts-Instanzen. Bei 5 Aktivitäten braucht das MILP 67,6 s, das indexierte CP 0,09 s, ein 750× Speed-up. Die direkte CP-Übersetzung allein bringt bei 5 Aktivitäten 20× über das MILP und zeigt, dass selbst ein mechanischer Paradigmenwechsel hier zahlt.
Das Deliverable ist mehr als eine Laufzeitzahl: Es ist eine Methodik zur Wahl des richtigen Paradigmas pro Problemklasse, und ein klarer negativer Befund (Intervall-Variablen helfen nicht), der das Team davor schützt, CP-SATs Intervall-Features auf ähnlichen Problemen in Zukunft zu überversprechen.
Technischer Deep Dive
Das Modell hinter dem Ergebnis.
Das Modell
Das aktivitätsbasierte Scheduling-Problem von Pougala et al. (2021) erzeugt einen Tagesablauf für eine Person: Welche Aktivitäten ausführen, in welcher Reihenfolge, zu welcher Anfangszeit, wie lange, an welchem Standort, mit welchem Verkehrsmodus, um eine Nutzenfunktion zu maximieren, die Abweichungen vom gewünschten Schedule bestraft (Früh-/Spät-Start-Strafen, Kurz-/Lang-Dauer-Strafen, Reisezeit-Strafe). Jede der drei CP-Varianten unten kodiert dasselbe Optimierungsproblem; die Unterschiede sind, wie jede Aktivitätsduplikation und Intervall-Logik ausdrückt.
Gemeinsame Nutzen-Zielfunktion. Die deterministischen Straf-Terme V hängen von Flexibilitätsparametern pro Aktivität ab, wie sehr die Person bereit ist, früher/später zu starten oder kürzere/längere Dauern zu akzeptieren. Die stochastischen Terme U sind Gumbel(0, 1)-Fehler (für den generischen Schedule-Geschmacks-U) plus Per-Aktivität-Fehlerfunktionen über Dauer, Anfangszeit, Modus und Sequenzierung. Alle vier CP-Varianten und das MILP optimieren dieselbe Zielfunktion; die einzigen Unterschiede sind, wie sie die Zulässigkeits-Constraints unten kodieren.
Tages-Summe und Sequenzierung. Die Gesamtzeit für Aktivitäten plus Inter-Aktivitäts-Reise muss der Tageslänge T entsprechen. Die Implikation z_ab ⟹ (x_a + τ_a + ρ = x_b) ist die Schlüssel-Constraint, die Anfangszeit-Information entlang der gewählten Sequenz propagiert. Im MILP wird sie zu zwei ≤-Constraints big-M-linearisiert; in CP ist sie eine native Implikation, die CP-SATs Propagator direkt behandelt, daher kommt ein wesentlicher Teil des Speed-ups.
Direkte Übersetzung: MILPs Aktivitätsduplikat-Trick beibehalten. Jede (Standort, Modus)-Kombination einer Aktivität ist eine separate Entscheidungsvariable, mit der Gruppen-Constraint Σ ω_b ≤ 1, die sagt, dass nur eine Kopie einer Aktivität in den Schedule kommt. Das bläst |A| um den Faktor |L_a| × |M| auf. Das direkte CP läuft bei 5 Aktivitäten 20× schneller als das MILP rein aus CP-SATs besserem Umgang mit den Implikations-Constraints, keine strukturelle Änderung.
Indexierte Reformulierung: aufhören zu duplizieren, anfangen zu indexieren. Modus m_a und Standort l_a werden zu Entscheidungsvariablen pro Aktivität (keine Duplikation). Reisezeiten für alle (Modus, Quelle, Ziel)-Kombinationen sind in einem flachen Array D der Grösse |M| × |L|² + 1 gespeichert. Die ELEMENT-globale-Constraint erzwingt t_ab = D[i_ab], wobei i_ab der berechnete Index in D ist. Das ist die strukturelle Änderung, die die zusätzliche Grössenordnung bringt, CP-SATs ELEMENT-Propagator ist schärfer als das, was die direkte Version offenlegt.
Modus-Konsistenz auf Touren weg von zu Hause. Sobald die Aktivitätsduplikation weg ist (indexierte Version), wird die Regel ‘wenn du das Auto zu Aktivität a genommen hast und b nicht zu Hause ist, musst du das Auto auch bei b haben’ zu zwei sauberen Implikationen statt der verzwickten Big-M-Conditionals des MILP. Das ist exemplarisch: Jede Regel, die das MILP über z_ab × kontinuierliche Variablen kodiert, wird zu einer Ein-Zeilen-CP-Implikation.
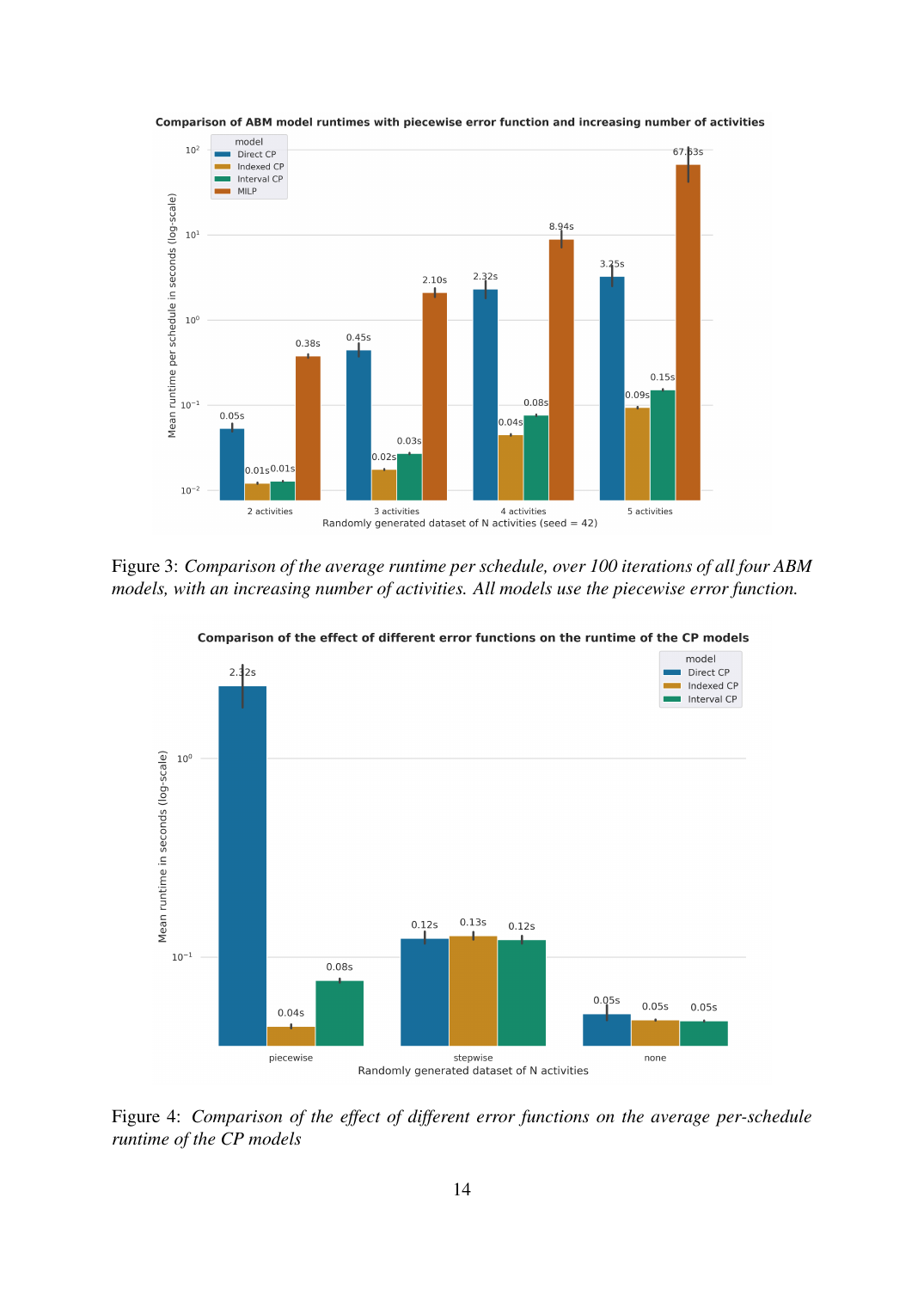
Intervall-Variablen mit NO_OVERLAP. Fügt optionale Intervalle (aktiv nur, wenn ω_a = 1) und die CP-SAT-NO_OVERLAP-globale-Constraint hinzu, der Lehrbuch-Weg, ‘keine zwei Aktivitäten gleichzeitig’ in CP-SAT auszudrücken. Der negative Befund: Das ist 1,5–2× langsamer als die indexierte Version, weil die bestehende Zeitkonsistenz-Implikation z_ab ⟹ (x_a + τ_a + t_ab = x_b) jede Aktivität bereits in Sequenz pinnt und NO_OVERLAP redundant macht. Die Constraint ist technisch gültig, aber aktiv schädlich, sie zwingt CP-SAT, mehr Status zu verfolgen, ohne neue Propagation freizuschalten.
Skalierung. Die MILP-Laufzeit wächst um ~10× pro hinzugefügter Aktivität (0,38 s → 67,6 s von N=2 auf N=5). Das indexierte CP wächst nur um einen Faktor 9 über den gesamten Bereich (0,01 s → 0,09 s), was bei N=5 einen 750×-Vorteil ergibt. Der Vorteil potenziert sich: Die tiefere Frage in der Schlussfolgerung ist, ob die Lücke vollständig vom Paradigma kommt (CP-Propagation vs. Branch-and-Bound) oder teilweise von Zeitdiskretisierung (CP erzwingt ganzzahlige Zeit, was den Entscheidungsraum schrumpft). Das Team markiert das als zukünftige Forschungsfrage, und es zählt, denn wenn der Speed-up grösstenteils aus Diskretisierung kommt, könnte das MILP einen Teil der Lücke mit eigener Diskretisierung schliessen.
Das Headline-Ergebnis ist der 750×-Speed-up, aber das *interessante* Ergebnis ist der negative Befund zu Intervall-Variablen. CP-SATs Intervall-und-NO_OVERLAP-Feature-Set wird als Killer-Kombi für Scheduling vermarktet, und für Job-Shop-Scheduling ist es das absolut. Aber bei diesem aktivitätsbasierten Scheduling-Problem erledigt die bestehende Zeitkonsistenz-Implikation bereits die Arbeit, die NO_OVERLAP leisten würde; die Intervall-Schicht hinzuzufügen ist reiner Overhead. Drei Lektionen für die Klienten-Arbeit: (1) Paradigmenwahl zählt mehr als Parameter-Tuning, wenn die Problemstruktur zu den Stärken eines Solvers passt, (2) idiomatische Reformulierungen schlagen direkte Übersetzungen um eine weitere Grössenordnung nach dem Paradigmenwechsel, (3) flashige Features sind nicht gratis, manchmal sind sie langsamer als die langweilige Formulierung, die bereits funktioniert.
Benchmark
Durchschnittliche Lösezeit pro Schedule auf zufällig generierten Aktivitäts-Datensätzen (RANDOM-2 bis RANDOM-5), 100 Iterationen pro (Modell, Datensatz)-Paar mit frischen Fehlerparametern jede Iteration, stückweise Fehlerfunktion in der Zielfunktion. Zeiten in Sekunden. Alle vier Modelle finden Schedules vergleichbarer Qualität (Zielfunktionswerte innerhalb des Rauschens), die Unterschiede sind rein Laufzeit.
| # Aktivitäten | MILP | Direct CP | Indexed CP | Interval CP | Indexed / MILP Speed-up |
|---|---|---|---|---|---|
| 2 | 0,38 s | 0,05 s | 0,01 s | 0,01 s | 38× |
| 3 | 2,10 s | 0,45 s | 0,02 s | 0,03 s | 105× |
| 4 | 8,94 s | 2,32 s | 0,04 s | 0,08 s | 224× |
| 5 | 67,6 s | 3,25 s | 0,09 s | 0,15 s | 751× |
Das MILP skaliert wie ~10× pro hinzugefügter Aktivität, eine Lehrbuch-Branch-and-Bound-Explosion, sobald der Entscheidungsbaum wächst. Die direkte CP-Übersetzung flacht nach 3 Aktivitäten ab (sie profitiert von CP-SATs Propagations-Engine, erbt aber den Aktivitätsduplikat-Aufwand). Das indexierte CP erreicht nahezu flache Skalierung: 0,01 → 0,09 s über den ganzen Bereich, ein 9×-Wachstum für 2,5× mehr Aktivitäten. Das Intervall-CP ist konsistent 1,5–2× langsamer als das indexierte, der negative Befund. Die Lücke wächst schnell: von 38× auf der kleinsten Instanz auf 751× auf der grössten. Auf einer separaten Achse (Komplexität der Zielfunktion) legt die stückweise Fehlerfunktion die grösste CP-interne Lücke offen: direkt = 2,32 s vs. indexiert = 0,04 s vs. Intervall = 0,08 s bei N = 5. Mit Null- oder Schritt-Fehlerfunktion schliessen alle CP-Varianten in ~0,05–0,12 s, der Komplexitätsvorteil der indexierten Version zeigt sich nur unter realistischen Zielfunktions-Formen.
Aus den Unterlagen

![Abschnitt 3.4, die indexierte Reformulierung. Das Reisezeit-Array D wird auf Grösse |M||L|² + 1 abgeflacht; der Index i_ab = |L|² m_a + |L| l_a + l_b wird aus den Entscheidungsvariablen m_a, l_a, l_b berechnet; ELEMENT(i_ab, D, t_ab) erzwingt t_ab = D[i_ab]. Das ist die strukturelle Änderung, die eine weitere Grössenordnung über die direkte Übersetzung bringt. Modus-Konsistenz wird zu einer sauberen Zwei-Zeilen-Implikation (Gleichungen 49–52) statt der verzwickten Big-M-Conditionals, die das MILP braucht.](/figures/comparative/p-10.png)
Techniken
- Constraint Programming mit CP-SAT
- Gemischt-ganzzahlige Programmierung (MILP-Baseline)
- ELEMENT-globale-Constraint
- Implikations-Constraints als First-Class-Objekte
- Optionale Intervall-Variablen + NO_OVERLAP
- Zeitdiskretisierung für CP-Kompatibilität
Stack
- Python
- Google OR-Tools CP-SAT
- CPLEX (MILP-Baseline)
- Pougala et al. 2021 MILP
Ein Problem wie dieses?