Schweizerische Bundesbahnen (SBB) · Team Verkehrsnachfrage-Prognose
68 Verhaltensparameter der Schedule-Flexibilität von Schweizer Arbeitnehmern
Maximum-Likelihood-Schätzung auf 10’110 echten Mikrozensus-Schedules, die empirische Kalibrierung, die jedes aktivitätsbasierte Verkehrsnachfrage-Modell anstelle von Vermutungen einsetzen kann
Wenn zwei Aktivitäten am selben Tag kollidieren, welche bewegt sich? Streckt ein Schweizer Pendler den Mittag oder verkürzt er die Arbeit? Schiebt er Freizeit nach hinten oder lässt er sie ganz weg? Bis jetzt füllten Verkehrsmodelle diese Zahlen per Vermutung.
Gemeinsam mit SBB und EPFL haben wir am publizierten Journal-Paper mitgearbeitet, das diese Zahlen direkt aus Daten zieht. Das Ergebnis ist eine empirische, begutachtete Antwort darauf, wie flexibel jeder Teil eines Schweizer Arbeitstags wirklich ist, und die Grundlage für die Verhaltenskalibrierung von SIMBA MOBi.
Die Herausforderung
Bestehende aktivitätsbasierte Modelle wählen einen Flexibilitätskoeffizienten pro Aktivitätstyp, von Hand. Das kann nicht erfassen, dass Arbeitnehmer Mittag dehnen, aber den Arbeitsblock selten verschieben, oder dass Einkaufen flexibler ist als ein Kind abholen.
Die SBB brauchte Parameter, die auf beobachtetem Schweizer Verhalten beruhen, rigoros genug geschätzt, um ein publiziertes Modell zu tragen, und beherrschbar genug, um in den Vollbevölkerungs-Simulationen zu laufen.
Unser Vorgehen
Wir haben Flexibilität als Vektor von Koeffizienten in einem nutzenmaximierenden MILP behandelt und sie per Maximum Likelihood gegen 10 110 bereinigte Schedules aus dem Schweizer Mikrozensus für Mobilität und Verkehr geschätzt, mit dem Standard-Logit-Rahmen über ein kompetitives Choice Set pro Person.
Validiert haben wir, indem wir die geschätzten Parameter zurück durch das MILP für ≈ 50 000 Vollzeit-Arbeitnehmer in Lausanne laufen liessen und die simulierten Aktivitätsprofile gegen den empirischen Mikrozensus verglichen haben.
Das Ergebnis
Deliverable: eine publizierte, peer-reviewed empirische Kalibrierung der Schedule-Flexibilität von Schweizer Arbeitnehmern, 68 statistisch signifikante Verhaltensparameter, die jedes aktivitätsbasierte Verkehrsnachfrage-Modell anstelle von Vermutungen einsetzen kann. Das Framework erreicht ρ̄² = 0,154 auf der 10’110-Schedule-Stichprobe und simuliert ~45’000 Lausanner Arbeitnehmer in rund einer Stunde auf einem 48-Kern-Server. Open Access publiziert in Transportation (Springer), CC BY 4.0.
Das Verhaltensbild ist scharf: Mittag ist die mit Abstand starrste Aktivität im Tag eines Schweizer Arbeitnehmers (β^short = −7,61, pro Stunde rund 350× empfindlicher gegen einen kurzen Mittag als gegen einen kurzen Arbeitstag). Morgenarbeit hat ein enges Startzeit-Ziel um 7:30, Heim-nach-Arbeit zieht stark Richtung 18:00, und abendliche Freizeit absorbiert die Restflexibilität. Genau das sind die Muster, gegen die Verkehrsnachfrage-Modelle kalibriert werden müssen, aber bis jetzt wurden sie von Hand eingetragen statt aus Daten geschätzt.
Technischer Deep Dive
Das Modell hinter dem Ergebnis.
Das Modell
Der Gesamtnutzen eines Kandidaten-Schedules zerlegt sich in pro-Aktivität-Strafen für das Verfehlen der gewünschten Anfangszeit und Dauer, plus eine Reise-Disutility auf jedem Beinabschnitt. Jede Strafe ist asymmetrisch: zu früh kann mehr oder weniger weh tun als zu spät, dasselbe für Dauer.
Gesamtnutzen des Schedules. Sekundäre Aktivitäten werden einzeln bestraft; primäre und Heim-Aktivitäten teilen sich ein Tages-Dauer-Budget.
Asymmetrische stückweise-lineare Strafe rund um die gewünschte Anfangszeit x_a*. β^early und β^late sind die Parameter, die wir schätzen.
Spiegelstrafe rund um die gewünschte Dauer τ_a*. β^short und β^long werden pro Aktivitätscluster geschätzt.
Logit-Wahrscheinlichkeit über das Choice Set C_n für Person n sowie die Maximum-Likelihood-Zielfunktion über den realisierten Schedule i*_n. Die Schätzung läuft in PandasBiogeme.
Der Schätzer liefert einen einzigen Vektor β̂ ∈ ℝ⁶⁸, der in einer einzigen, statistisch belastbaren Sprache erfasst, wie starr jedes Aktivitätscluster im Tag eines Schweizer Vollzeit-Arbeitnehmers ist.
Benchmark
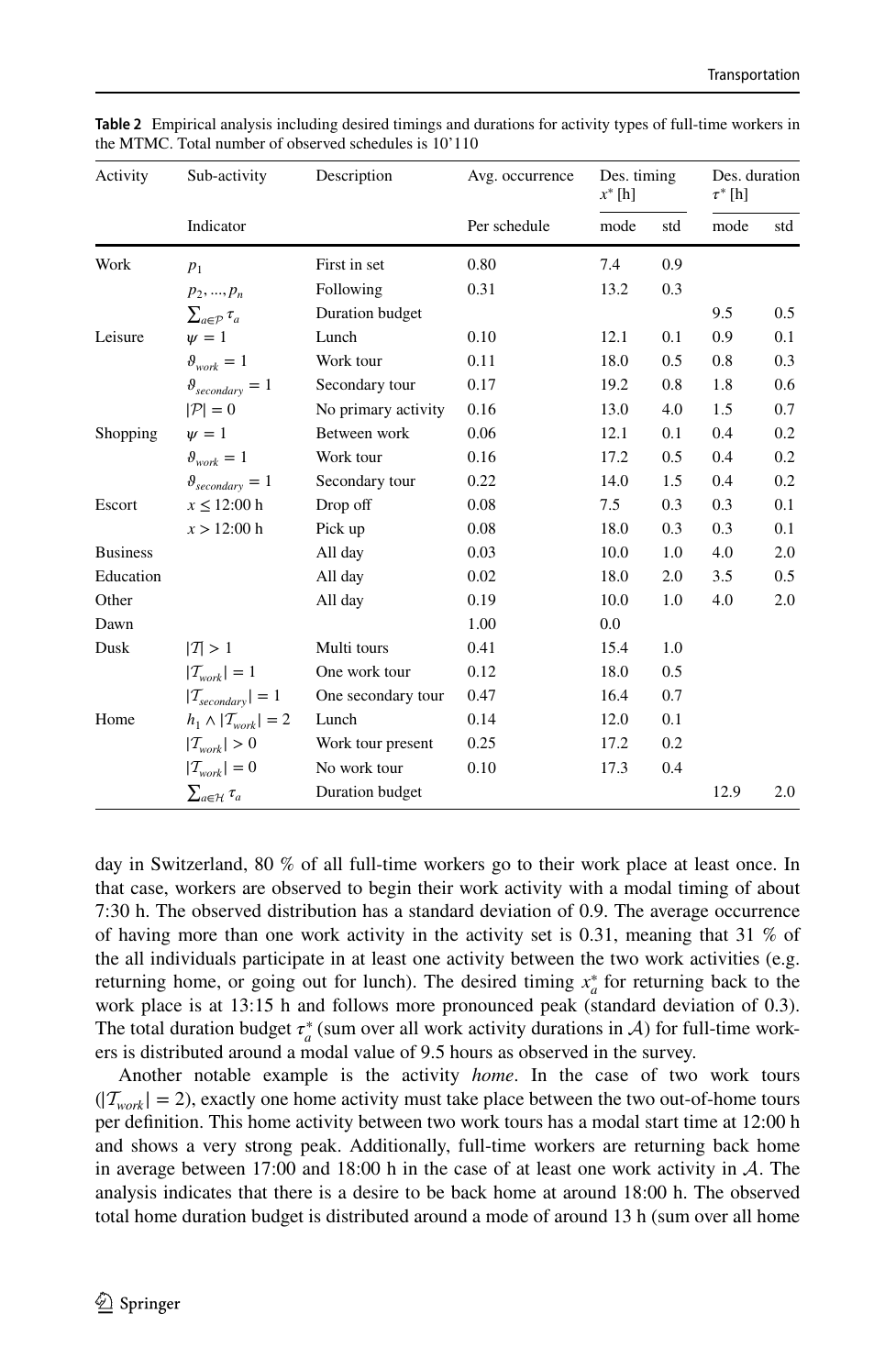
Geschätzte Flexibilitätspräferenzen für ausgewählte Aktivitätscluster (Tabelle 3 des Journal-Papers).
| Aktivität / Cluster | β^early | β^late | β^short | β^long |
|---|---|---|---|---|
| Arbeit : erste im Set | −0,518 | −0,401 | - | - |
| Arbeit : folgend | −0,317 | 0 | - | - |
| Arbeit : Tages-Dauer-Budget | - | - | −0,022 | 0 |
| Freizeit : Mittag | −1,587 | −0,760 | −7,614 | −1,314 |
| Freizeit : abendliche Sekundärtour | −0,058 | 0 | −3,087 | −0,693 |
| Einkauf : in einer Sekundärtour | −0,229 | −0,468 | −6,003 | −0,746 |
| Begleitung : Abgabe | −1,106 | 0 | 0 | −4,171 |
| Heim : Mittag | −2,189 | −1,067 | - | - |
| Heim : mit Arbeitstour | −0,072 | −0,397 | - | - |
| Heim : Tages-Dauer-Budget | - | - | 0 | −0,373 |
Negative Zahlen sind Nutzenstrafen pro Stunde Abweichung; 0 bedeutet, dass der Parameter auf 5 % nicht signifikant war. Stärkstes Muster: Mittag ist hochgradig starr (β^short = −7,61, Arbeitnehmer wollen wirklich keinen kurzen Mittag), und die Heim-zum-Mittag-Rückkehr ist sogar starrer als die Arbeit selbst. Morgenarbeit ist beim Startzeitpunkt doppelt so starr wie Nachmittagsarbeit. Abendliche Freizeit nimmt die Flexibilität auf. Stichprobe 10 110 bereinigte Vollzeit-Arbeitnehmer-Schedules, 68 Parameter alle auf 5 % signifikant, ρ̄² = 0,154, Log-Likelihood-Verbesserung −57 443,43 → −48 548,23, Schätzzeit ≈ 12,3 h auf 40 Kernen.
Aus den Unterlagen

Techniken
- Maximum-Likelihood-Schätzung unter einem MILP-Simulator
- Choice-Set-Konstruktion (wahrscheinliche + zufällige Alternativen)
- Logit-Modelle auf Schedule-Alternativen
- Zeitkontinuierliches Scheduling mit stückweise-linearer Nutzenfunktion
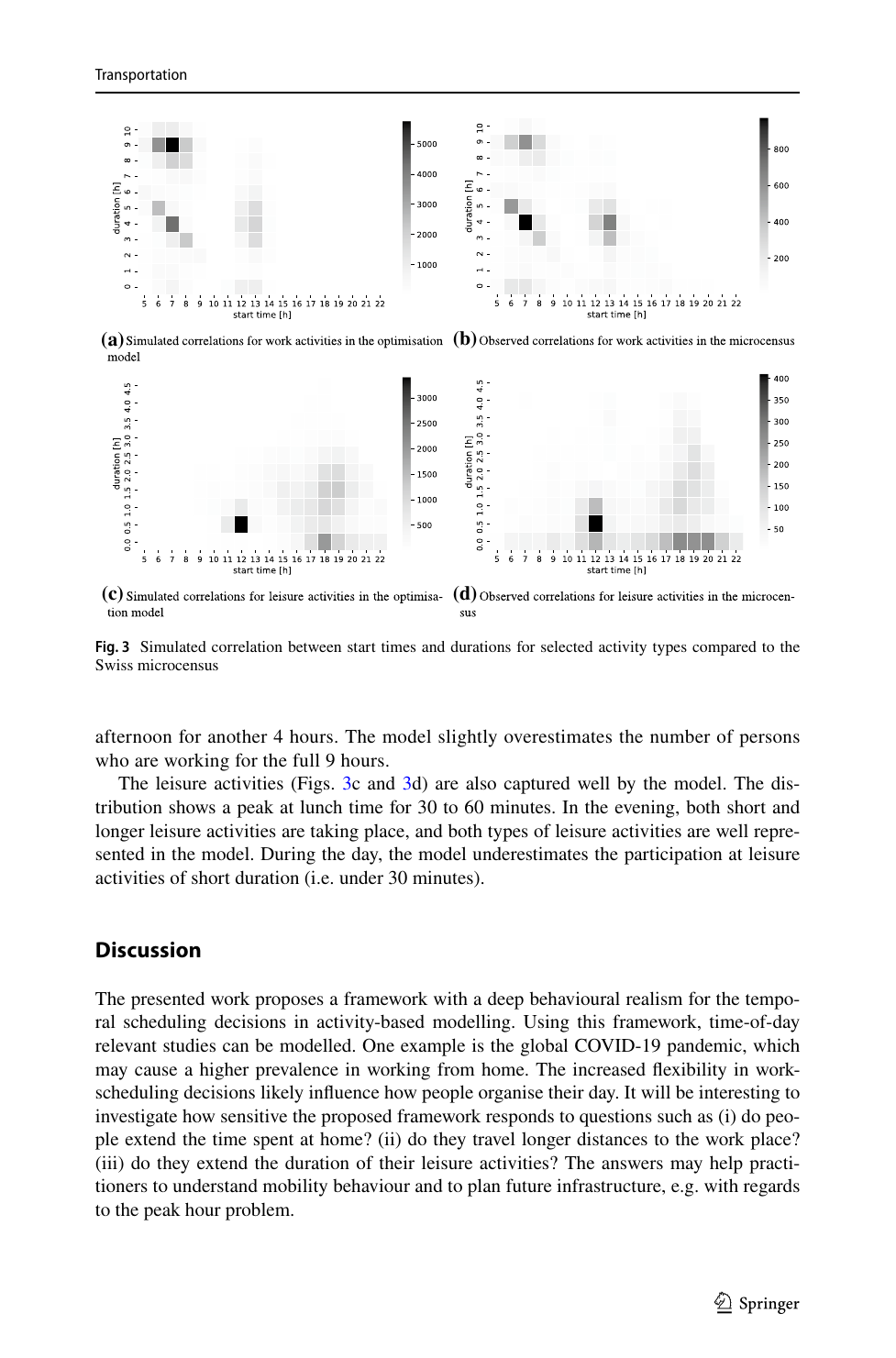
- Validierung über simulierte Aktivitätsprofile und 2D-Heatmaps
Stack
- Python
- PandasBiogeme
- OR-Tools
- SCIP
- Ray (parallele Ausführung)
- Schweizer MTMC-Mikrozensus
Ein Problem wie dieses?