Schweizerische Bundesbahnen (SBB) · Bahnbetreiber · SIMBA-MOBi-Modellierungsteam
Ein stadtweiter Aktivitäten-Scheduler, der den Schweizer Mikrozensus auf einem Open-Source-Stack reproduziert
Ein zeitkontinuierliches MILP-Framework, mit SBB an der EPFL entwickelt, kalibriert auf 10’110 echten Mikrozensus-Schedules und Ende-zu-Ende auf 46’970 Schedules einer synthetischen Lausanner Bevölkerung gerechnet — ohne einen einzigen regelbasierten Patch
Verkehrsnachfrage-Prognose hängt davon ab, was reale Menschen tagsüber tatsächlich tun, wann sie arbeiten, einkaufen, Mittag essen, nicht nur davon, wie viele Autos auf der Strasse sind. Die meisten operativen Modelle mogeln auf der zeitlichen Ebene mit Heuristiken und verlieren ihre Realitätsnähe, sobald etwas Disruptives passiert.
Gemeinsam mit SBB und EPFL haben wir ein echtes Optimierungsmodell für die Zeitdimension gebaut. Ein gemischt-ganzzahliges Programm entscheidet für jede Person den gesamten Tagesablauf gemeinsam, kalibriert auf realen Schweizer Mikrozensus-Daten. Das Ergebnis ist eine stadtweite Simulation, deren Aktivitätsprofile mit den empirischen Beobachtungen übereinstimmen, ganz ohne heuristisches Nachflicken.
Die Herausforderung
Klassische aktivitätsbasierte Verkehrsmodelle simulieren Entscheidungen sequentiell, was, dann wann, dann wo, dann wie, wodurch sie für Zielkonflikte blind werden. Zwei Aktivitäten konkurrieren um dieselbe Stunde? Vierzigtausend Personen wollen gleichzeitig pendeln und einkaufen? Sequentielle Modelle raten; sie optimieren nicht.
Die SBB brauchte ein Framework, das realistisch genug ist, um die Verkehrszuweisung in MATSim zu speisen, schnell genug, um vollständige Tagesabläufe für eine ganze Stadt zu simulieren, und flexibel genug, um grosse Verhaltensänderungen wie den Anstieg des Homeoffice aufzunehmen.
Unser Vorgehen
Wir haben die zeitliche Ebene in ein echtes Optimierungsproblem verwandelt: Anfangszeit, Dauer und Aktivitätssequenz jeder Person werden gemeinsam von einem gemischt-ganzzahligen linearen Programm bestimmt, mit aus Daten geschätzten Nutzenparametern. Die nicht-temporalen Entscheidungen (wo, was, wie) bleiben in den bestehenden Discrete-Choice-Modellen der SBB und gehen als feste Inputs in den Optimierer ein.
Wir haben das Ganze auf dem Open-Source-Solver SCIP über OR-Tools deployt, so braucht die operative Pipeline keine kommerzielle Lizenz, und gegen den Schweizer Mikrozensus auf der Vollzeit-Arbeitstätigen-Teilpopulation in Lausanne validiert.
Das Ergebnis
Deliverable: ein kalibriertes, validiertes aktivitätsbasiertes Scheduling-Framework, das Zeitkonflikte in Tagesabläufen über ein nutzenmaximierendes MILP auflöst, gebaut auf dem Open-Source-SCIP-/OR-Tools-Stack (null Lizenzkosten für kommerzielle Solver). Veröffentlicht auf der STRC 2021 in Co-Autorschaft mit SBB und EPFL, im Rahmen der Innosuisse-finanzierten Zusammenarbeit SBB × EPFL zur Verkehrsnachfrage-Modellierung (Projekt 2155006680).
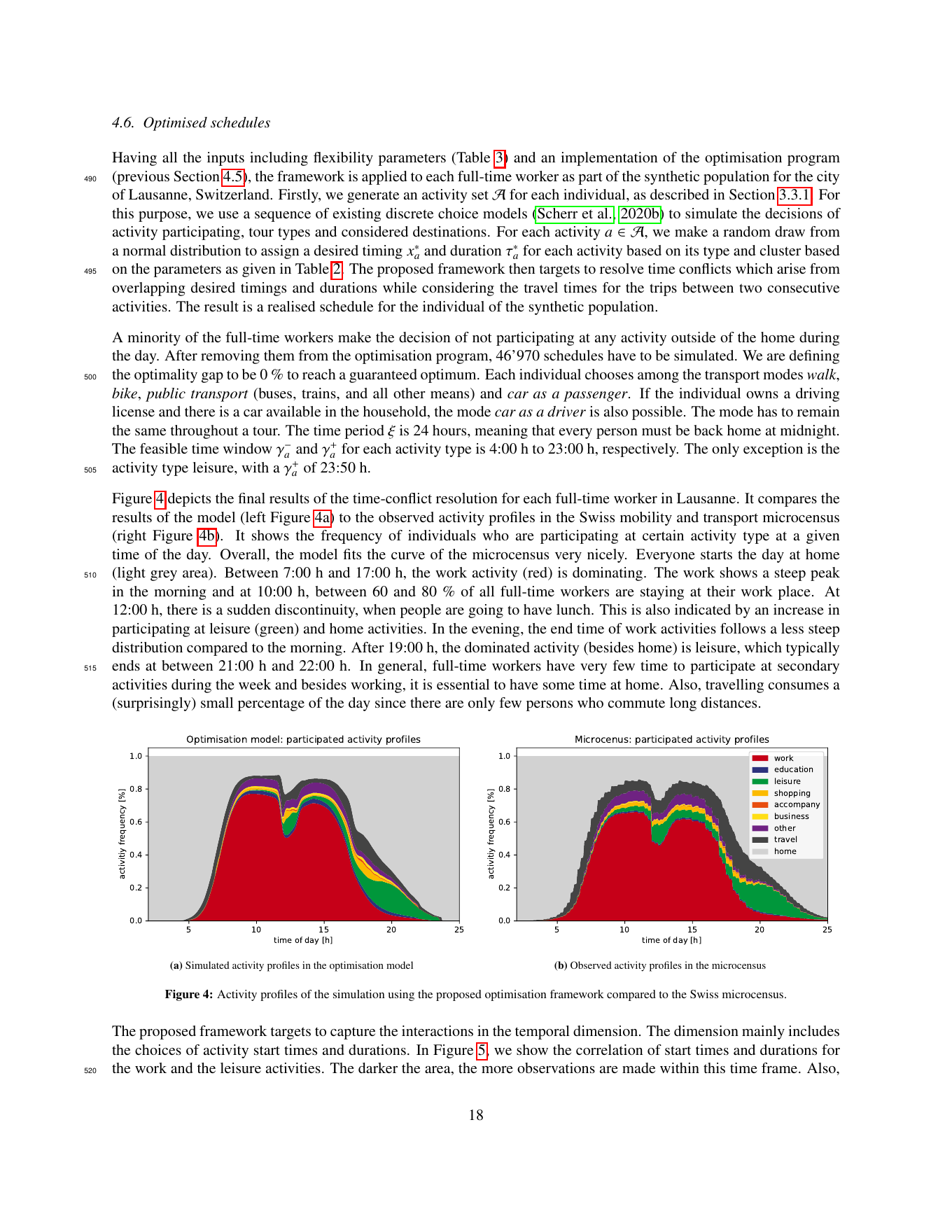
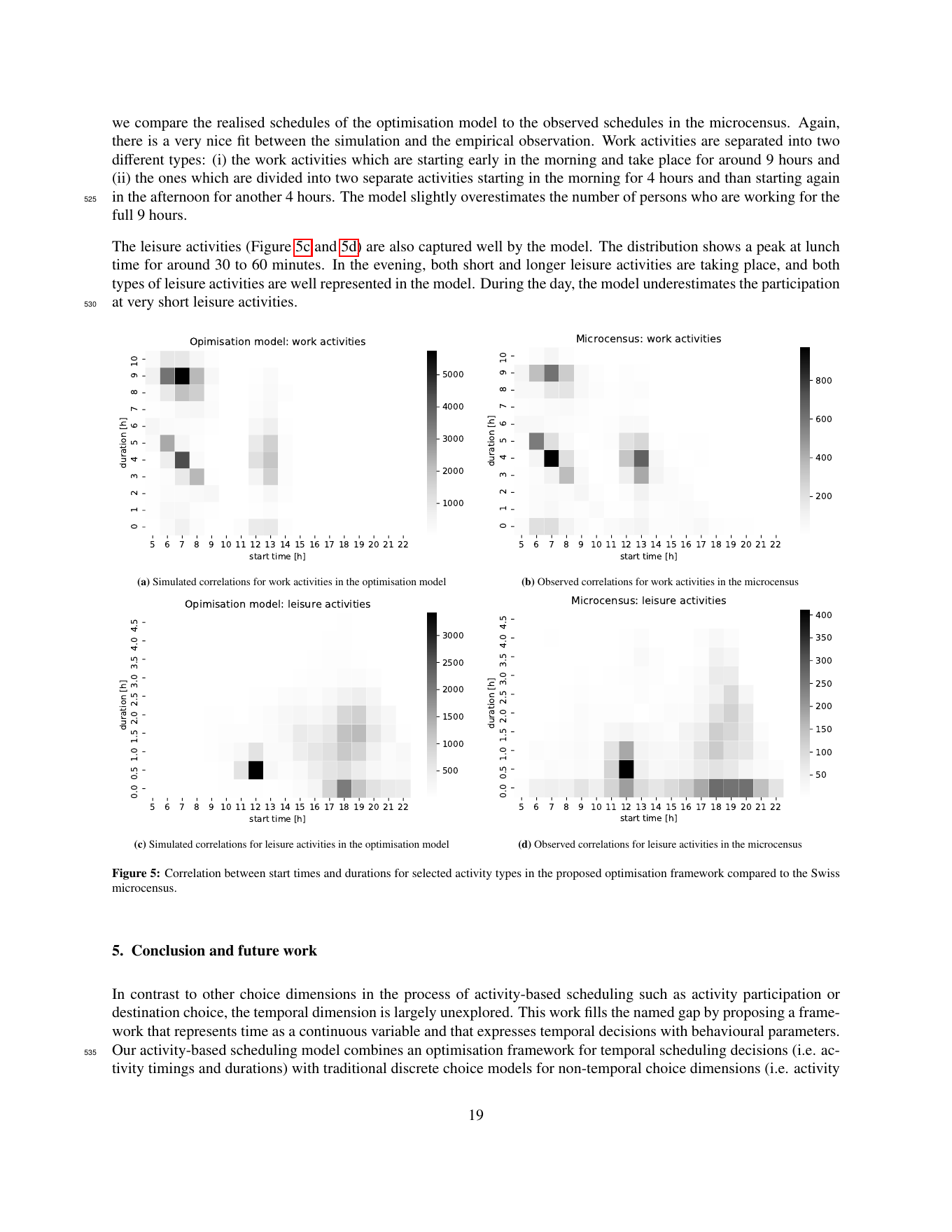
Auf einer synthetischen Lausanner Population von 46’970 Schedules reproduzieren die simulierten Aktivitätsprofile jede empirische Signatur des Schweizer Mikrozensus, morgendliche Arbeitsspitze, Mittags-Senke, abendliches Freizeit-Fenster, Multi-Tour-Struktur, ohne einen einzigen regelbasierten Patch. Das Framework kalibriert 64 Verhaltensparameter auf 10’110 echten Mikrozensus-Schedules und erreicht ρ̄² = 0,165.
Technischer Deep Dive
Das Modell hinter dem Ergebnis.
Das Modell
Jede Person i hat eine feste Menge an Aktivitäten A_i, die innerhalb eines 24-Stunden-Budgets ξ ausgeführt werden müssen. Das MILP wählt Anfangszeit x_a, Dauer τ_a, Reisezeit tt_a zur nächsten Aktivität sowie einen binären Sequenzindikator z_{ab} (= 1, falls a unmittelbar von b gefolgt wird). Die Zielfunktion ist der Gesamtnutzen des Tagesablaufs, eine Summe aus Strafen für Abweichungen vom gewünschten Anfangs- und Dauerverhalten, plus einer Reisezeit-Disutility.
Gesamtnutzen des Schedules. Sekundäre Aktivitäten werden einzeln bestraft; primäre und Heim-Aktivitäten teilen sich ein Tages-Dauer-Budget.
Stückweise-lineare Zeitstrafe rund um die gewünschte Anfangszeit x_a*. Asymmetrisch, zu früh kann mehr oder weniger weh tun als zu spät.
Spiegelstrafe rund um die gewünschte Dauer τ_a*. Aus Mikrozensus-Daten per Maximum Likelihood geschätzt.
Big-M-Sequenzkonsistenz. Bei z_{ab} = 1 kollabiert das Ungleichungspaar zur Gleichung x_b = x_a + τ_a + tt_a; sonst sind die Schranken inaktiv.
Das Zeitbudget füllt den 24-Stunden-Tag exakt. Jede Aktivität (ausser den Endpunkten dawn/dusk) hat genau einen Vorgänger und einen Nachfolger.
Die Flexibilitätsparameter β^early, β^late, β^short, β^long sind unbekannt pro Aktivitätstyp. Wir schätzen sie per Maximum Likelihood: Für jeden beobachteten Schedule im Mikrozensus bauen wir ein kompetitives Choice Set, bewerten jede Alternative mit der obigen Nutzenfunktion und passen die Parameter so an, dass der beobachtete Schedule unter einem Logit-Modell am wahrscheinlichsten wird. Die Parameter fliessen dann zur Simulationszeit in dasselbe MILP zurück.
Benchmark
Geschätzte Flexibilitätsparameter für ausgewählte Aktivitätscluster (signifikant auf dem 5-%-Niveau).
| Aktivität / Cluster | β^early | β^late | β^short | β^long |
|---|---|---|---|---|
| Arbeit : Morgenstart | −0,615 | −0,436 | - | - |
| Arbeit : Nachmittagsstart | −0,406 | 0 | - | - |
| Arbeit : Tages-Dauer-Budget | - | - | −0,022 | 0 |
| Freizeit : Mittag (Sub-Tour) | −1,610 | −0,821 | −7,550 | −1,360 |
| Freizeit : abendliche Sekundärtour | −0,076 | 0 | −3,060 | −0,692 |
| Einkauf : in einer Sekundärtour | −0,239 | −0,486 | −5,910 | −0,721 |
| Heim : nach der Arbeit | −0,073 | −0,596 | - | - |
| Heim : Tages-Dauer-Budget | - | - | 0 | −0,354 |
Negative Zahlen sind Strafen (Nutzenverlust pro Stunde Abweichung). Mittag ist die starrste Aktivität, sowohl was Zeitabweichung als auch was Verfehlen der gewünschten Dauer angeht. Der Arbeitsanfang am Morgen ist starr, am Nachmittag deutlich flexibler. Die Heim-Spät-Strafe (β^late = −0,596) fängt die gut dokumentierte Präferenz ein, am frühen Abend zu Hause zu sein. Stichprobe 10 110 bereinigte Vollzeit-Arbeitnehmer-Schedules, ρ̄² = 0,165, Log-Likelihood von −57 295,58 auf −47 847,37 über 64 Parameter.
Aus den Unterlagen

Techniken
- Zeitkontinuierliches aktivitätsbasiertes Scheduling
- Gemischt-ganzzahlige lineare Programmierung über OR-Tools / SCIP
- Maximum-Likelihood-Schätzung der Nutzenparameter
- Choice-Set-Generierung (wahrscheinliche + zufällige Alternativen)
- Kopplung von MILP-Optimierung mit sequentiellen Discrete-Choice-Modellen
Stack
- Python
- OR-Tools
- SCIP
- Biogeme
- Ray (parallele Ausführung)
- MATSim-Integration
Ein Problem wie dieses?